## Flowchart: Experience-Driven LLM Reasoning System
### Overview
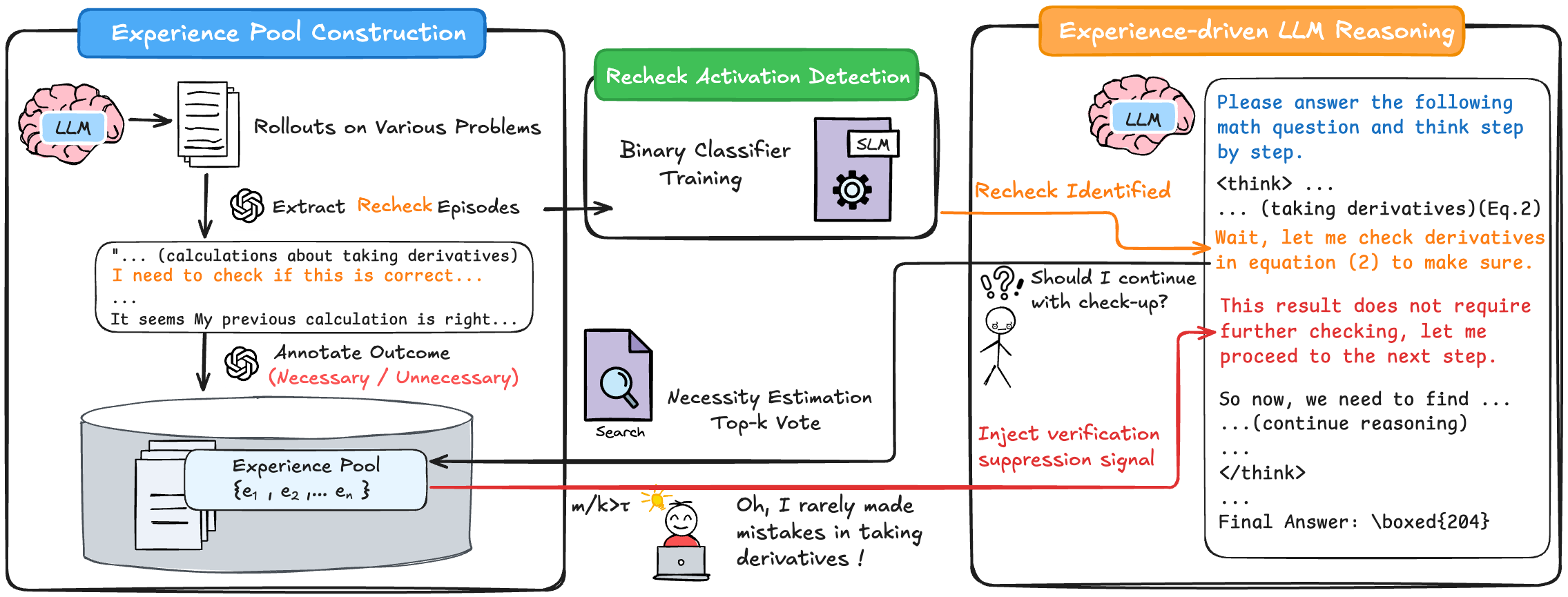
The flowchart illustrates a three-stage system for optimizing large language model (LLM) reasoning through experience-driven verification. It combines experience pool construction, recheck activation detection, and adaptive reasoning with verification suppression. Key elements include an LLM, experience pool, binary classifier, and feedback loops for error correction.
### Components/Axes
1. **Experience Pool Construction** (Blue Box)
- **Components**:
- LLM (brain icon)
- Rollouts on Various Problems (document icon)
- Experience Pool (database icon with {e₁, e₂, ..., eₙ})
- **Process Flow**:
- LLM generates rollouts → Extract recheck episodes → Annotate outcomes (Necessary/Unnecessary) → Store in Experience Pool
2. **Recheck Activation Detection** (Green Box)
- **Components**:
- Binary Classifier Training (gear icon)
- Necessity Estimation (magnifying glass)
- Top-k Vote (search icon)
- **Process Flow**:
- Experience Pool → Binary Classifier → Necessity Estimation → Top-k Vote
3. **Experience-driven LLM Reasoning** (Orange Box)
- **Components**:
- LLM (brain icon)
- Verification Suppression Signal (red arrow)
- Stick figure with laptop (human-in-the-loop element)
- **Process Flow**:
- LLM reasoning → Recheck Activation Detection → Verification Suppression → Adaptive reasoning
### Detailed Analysis
- **Experience Pool Construction**:
- Textual examples include:
- "I need to check if this is correct..."
- "It seems My previous calculation is right..."
- Outcomes are annotated as "Necessary" or "Unnecessary" (red text).
- **Recheck Activation Detection**:
- Binary classifier uses SLM (small language model) for training.
- Necessity Estimation employs a "Top-k Vote" mechanism (search icon).
- **Experience-driven LLM Reasoning**:
- LLM generates reasoning traces (e.g., "Please answer the following math question...").
- Verification suppression signal (red arrow) bypasses rechecks when confidence is high.
- Human-like stick figure expresses self-awareness: "Oh, I rarely made mistakes in taking derivatives!"
### Key Observations
1. **Feedback Loops**:
- Experience Pool → Recheck Detection → LLM Reasoning creates a closed-loop system for continuous improvement.
2. **Verification Suppression**:
- Red arrow indicates dynamic suppression of unnecessary checks based on confidence.
3. **Human-LLM Collaboration**:
- Stick figure represents meta-cognitive awareness of error patterns.
4. **Mathematical Context**:
- Explicit references to derivatives (Eq. 2) and equation-based reasoning.
### Interpretation
This system demonstrates a self-improving LLM framework where:
1. **Experience Pool** acts as a memory bank of past reasoning errors and successes.
2. **Binary Classifier** identifies when rechecks are statistically necessary, reducing computational overhead.
3. **Verification Suppression** optimizes efficiency by avoiding redundant checks when confidence is high.
4. The human-like element suggests the system incorporates meta-cognitive feedback, mimicking human learning from mistakes.
The architecture balances rigor (through systematic rechecks) and efficiency (via suppression signals), creating an adaptive reasoning pipeline that improves with accumulated experience. The mathematical focus (derivatives, equations) indicates specialization in STEM domains, while the stick figure metaphorizes the system's growing reliability through iterative learning.