\n
## Diagram: Agent Learning Paradigms
### Overview
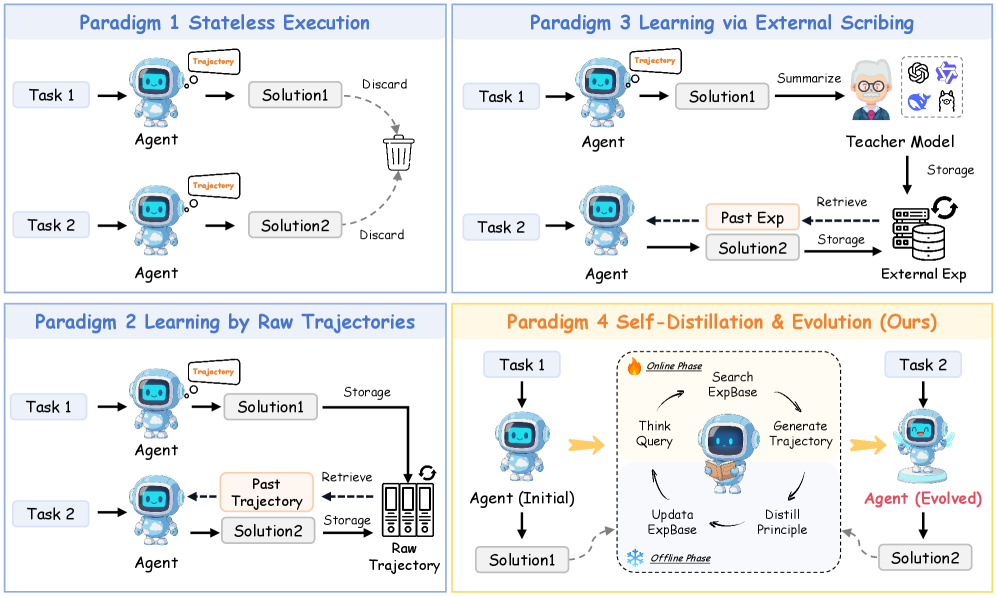
The image presents a comparative diagram illustrating four different paradigms for agent learning. Each paradigm is visually represented as a workflow, showing how an agent interacts with tasks and solutions. The paradigms are: Stateless Execution, Learning via External Scribing, Learning by Raw Trajectories, and Self-Distillation & Evolution. Each paradigm is visually separated into distinct quadrants.
### Components/Axes
The diagram doesn't have traditional axes. Instead, it uses visual flow and labeled components to convey information. Key components include:
* **Agent:** Represented by a blue robot icon.
* **Task 1 & Task 2:** Represented as rectangular boxes with the labels "Task 1" and "Task 2".
* **Trajectory:** Represented by curved arrows.
* **Solution 1 & Solution 2:** Represented as rectangular boxes with the labels "Solution1" and "Solution2".
* **Discard:** Represented by a trash can icon.
* **Summarize:** Represented by a speech bubble with an ellipsis.
* **Teacher Model:** Represented by a brain icon.
* **Storage:** Represented by a cylinder icon.
* **Past Exp:** Represented as a rectangular box with the label "Past Exp".
* **Retrieve:** Represented by an arrow pointing from storage.
* **Raw Trajectory:** Represented as a stack of rectangular boxes with the label "Raw Trajectory".
* **ExpBase:** Represented as a rectangular box with the label "ExpBase".
* **Online Phase:** Label indicating the online learning process.
* **Offline Phase:** Label indicating the offline learning process.
* **Think Query:** Represented by a brain icon.
* **Generate Trajectory:** Represented by a curved arrow.
* **Update:** Represented by an arrow pointing downwards.
* **Distill Principle:** Represented by a funnel icon.
* **Agent (Evolved):** Represented by a blue robot icon.
Each paradigm is labeled with a title in a colored bar at the top:
* Paradigm 1: Stateless Execution (Blue)
* Paradigm 3: Learning via External Scribing (Purple)
* Paradigm 2: Learning by Raw Trajectories (Green)
* Paradigm 4: Self-Distillation & Evolution (Ours) (Orange)
### Detailed Analysis or Content Details
**Paradigm 1: Stateless Execution (Blue)**
* Task 1: Agent generates a trajectory leading to Solution 1, which is then discarded.
* Task 2: Agent generates a trajectory leading to Solution 2, which is then discarded.
* The flow is simple: Task -> Agent -> Trajectory -> Solution -> Discard.
**Paradigm 3: Learning via External Scribing (Purple)**
* Task 1: Agent generates a trajectory leading to Solution 1, which is then summarized by a Teacher Model and stored.
* Task 2: Agent generates a trajectory leading to Solution 2. Past experience (Past Exp) is retrieved from storage and used to inform the solution.
* The Teacher Model is connected to storage, indicating it learns from past solutions.
**Paradigm 2: Learning by Raw Trajectories (Green)**
* Task 1: Agent generates a trajectory leading to Solution 1, which is stored.
* Task 2: Agent generates a trajectory leading to Solution 2. The past trajectory is retrieved from storage and used to inform the solution.
* Raw Trajectories are stored for later retrieval.
**Paradigm 4: Self-Distillation & Evolution (Orange)**
* Task 1: Agent (Initial) generates Solution 1.
* An "Online Phase" involves: Thinking Query, Searching ExpBase, Generating Trajectory.
* An "Offline Phase" involves: Updating ExpBase, Distilling Principle.
* This leads to an Agent (Evolved) which then tackles Task 2 and generates Solution 2.
* The process is iterative, with the agent evolving based on its experience.
### Key Observations
* Paradigm 1 is the simplest, discarding all solutions.
* Paradigm 3 relies on an external Teacher Model for learning.
* Paradigm 2 stores raw trajectories for future use.
* Paradigm 4 is the most complex, involving both online and offline phases for self-improvement.
* The "Ours" label on Paradigm 4 suggests this is the authors' proposed method.
* The use of arrows consistently indicates the flow of information or process.
### Interpretation
The diagram illustrates a progression in agent learning paradigms, from simple stateless execution to more sophisticated self-improvement techniques. The comparison highlights the trade-offs between simplicity and learning capability. Paradigm 1 is efficient but doesn't learn. Paradigms 2 and 3 demonstrate different approaches to leveraging past experience. Paradigm 4, the authors' method, aims to combine the benefits of both by allowing the agent to actively refine its knowledge base and improve its performance over time. The diagram suggests a shift from passive learning (receiving feedback from a teacher) to active learning (self-distillation and evolution). The inclusion of "Online Phase" and "Offline Phase" in Paradigm 4 indicates a potential for continuous learning and adaptation. The diagram is a high-level conceptual overview and doesn't provide specific details about the algorithms or implementation of each paradigm. It serves as a visual aid for understanding the core principles of each approach.