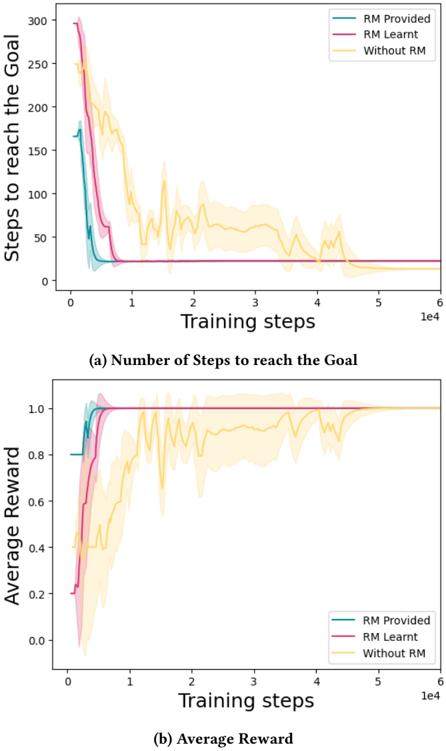
## Line Chart: Training Performance Comparison
### Overview
The image presents two line charts comparing the performance of a reinforcement learning algorithm under different conditions: with a Reward Model (RM) provided, with a Reward Model learned during training, and without a Reward Model. The top chart shows the number of steps to reach the goal, while the bottom chart shows the average reward. Both charts plot these metrics against the number of training steps. Shaded areas around each line represent the standard deviation.
### Components/Axes
* **X-axis (Both Charts):** Training steps, ranging from 0 to approximately 60,000 (6e4).
* **Y-axis (Top Chart):** Steps to reach the goal, ranging from 0 to 300.
* **Y-axis (Bottom Chart):** Average Reward, ranging from 0 to 1.1.
* **Legend (Both Charts):**
* RM Provided (Purple)
* RM Learnt (Teal)
* Without RM (Yellow)
### Detailed Analysis
**Chart (a): Number of Steps to reach the Goal**
* **RM Provided (Purple):** The line starts at approximately 280 steps, rapidly decreases to around 20 steps by 1000 training steps, and then plateaus around 15-20 steps for the remainder of the training period.
* **RM Learnt (Teal):** The line begins at approximately 270 steps, decreases more gradually than the "RM Provided" line, reaching around 50 steps by 1000 training steps. It continues to decrease, but with more oscillations, eventually leveling off around 30-40 steps.
* **Without RM (Yellow):** The line starts at approximately 260 steps, decreases slowly initially, then exhibits significant oscillations. It reaches a minimum of around 40 steps at approximately 2000 training steps, but then fluctuates between 40 and 80 steps for the rest of the training.
**Chart (b): Average Reward**
* **RM Provided (Purple):** The line starts at approximately 0.1, rapidly increases to around 0.9 by 1000 training steps, and then stabilizes around 0.9-1.0 for the remainder of the training.
* **RM Learnt (Teal):** The line begins at approximately 0.1, increases more gradually than the "RM Provided" line, reaching around 0.7 by 1000 training steps. It continues to increase, but with more oscillations, eventually leveling off around 0.8-0.9.
* **Without RM (Yellow):** The line starts at approximately 0.1, increases slowly initially, then exhibits significant oscillations. It reaches a maximum of around 0.7 at approximately 2000 training steps, but then fluctuates between 0.6 and 0.8 for the rest of the training.
### Key Observations
* Providing a Reward Model ("RM Provided") consistently results in the lowest number of steps to reach the goal and the highest average reward.
* Learning a Reward Model ("RM Learnt") improves performance compared to not using a Reward Model ("Without RM"), but does not reach the same level as providing a pre-defined Reward Model.
* The "Without RM" condition exhibits the most significant oscillations in both charts, indicating instability in the learning process.
* The standard deviation (represented by the shaded areas) is generally smaller for the "RM Provided" condition, suggesting more consistent performance.
### Interpretation
The data strongly suggests that a Reward Model is crucial for the effective training of this reinforcement learning algorithm. Providing a pre-defined Reward Model ("RM Provided") leads to faster learning and more stable performance. Learning a Reward Model during training ("RM Learnt") offers some improvement over not using a Reward Model at all ("Without RM"), but is less effective. The oscillations observed in the "Without RM" condition indicate that the algorithm struggles to learn a meaningful reward signal on its own, leading to inconsistent and suboptimal performance.
The two charts are directly related: a lower number of steps to reach the goal (Chart a) corresponds to a higher average reward (Chart b). This is expected, as reaching the goal quickly implies efficient learning and a strong reward signal. The consistent performance of the "RM Provided" condition highlights the importance of a well-defined reward function in reinforcement learning. The differences between the "RM Learnt" and "Without RM" conditions suggest that learning a reward function is a challenging task, and may require careful tuning or additional techniques to achieve optimal results.