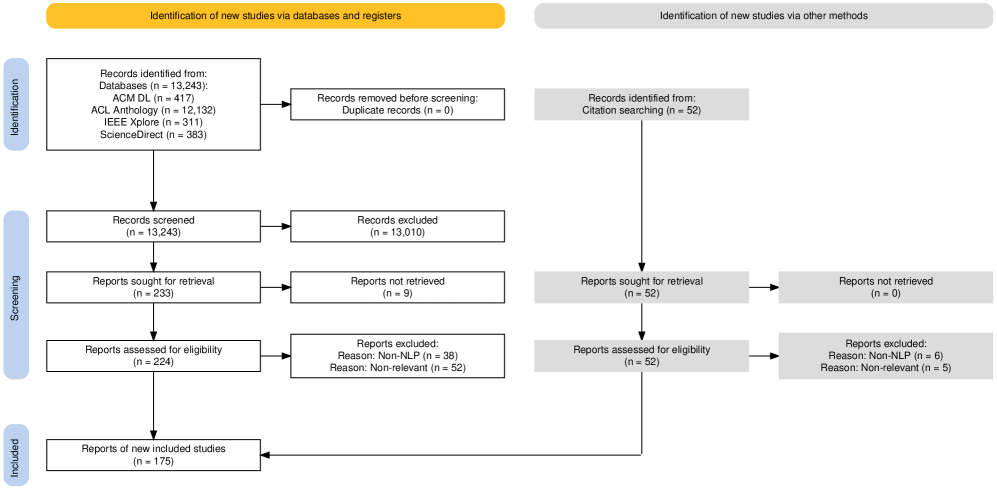
## Flowchart: Identification and Screening of Studies for Inclusion
### Overview
The flowchart illustrates a two-branch process for identifying and screening studies for inclusion in a systematic review. The left branch focuses on database/registry identification, while the right branch covers other methods (e.g., citation searching). Each branch includes steps for record identification, screening, eligibility assessment, and final inclusion. Numerical values in parentheses indicate the number of records or reports at each stage.
---
### Components/Axes
#### Left Branch (Database/Registry Identification)
1. **Identification of new studies via databases and registers**
- Records identified from:
- Databases (n = 13,243):
- ACM DL (n = 4,17)
- ACL Anthology (n = 12,132)
- IEEE Xplore (n = 3,11)
- ScienceDirect (n = 583)
- Records removed before screening: Duplicate records (n = 0)
- Records screened: (n = 13,243)
- Records excluded: (n = 13,010)
- Reports sought for retrieval: (n = 233)
- Reports not retrieved: (n = 9)
- Reports assessed for eligibility: (n = 224)
- Reports excluded:
- Reason: Non-NLP (n = 38)
- Reason: Non-relevant (n = 52)
- Reports of new included studies: (n = 175)
#### Right Branch (Other Methods)
1. **Identification of new studies via other methods**
- Records identified from: Citation searching (n = 52)
- Records sought for retrieval: (n = 52)
- Reports not retrieved: (n = 0)
- Reports assessed for eligibility: (n = 52)
- Reports excluded:
- Reason: Non-NLP (n = 6)
- Reason: Non-relevant (n = 5)
---
### Detailed Analysis
#### Left Branch
- **Initial Identification**: 13,243 records were identified from databases, with no duplicates removed.
- **Screening**: 13,243 records were screened, with 13,010 excluded (90.7% exclusion rate).
- **Retrieval**: 233 reports were sought for retrieval, but 9 (3.8%) could not be retrieved.
- **Eligibility Assessment**: 224 reports were assessed, with 90 excluded (40.2% exclusion rate):
- 38 (16.9%) excluded for Non-NLP.
- 52 (23.2%) excluded for Non-relevance.
- **Inclusion**: 175 studies were included.
#### Right Branch
- **Initial Identification**: 52 records were identified via citation searching.
- **Screening**: All 52 records were retrieved (0 exclusions).
- **Eligibility Assessment**: 52 reports were assessed, with 11 excluded (21.2% exclusion rate):
- 6 (11.5%) excluded for Non-NLP.
- 5 (9.6%) excluded for Non-relevance.
- **Inclusion**: The flowchart does not explicitly state the number of included studies for this branch, but it can be inferred as 52 - 11 = 41.
---
### Key Observations
1. **Scale Disparity**: The database/registry branch starts with 13,243 records, far exceeding the 52 records from citation searching.
2. **Exclusion Rates**:
- Database branch: 90.7% exclusion rate during screening, with 40.2% exclusion during eligibility assessment.
- Citation branch: 21.2% exclusion rate during eligibility assessment.
3. **Non-NLP Exclusions**: Non-NLP exclusions are more frequent in the database branch (38 vs. 6).
4. **Non-Relevance Exclusions**: Non-relevance exclusions are higher in the database branch (52 vs. 5).
---
### Interpretation
The flowchart highlights two distinct pathways for study identification:
1. **Database/Registry Method**:
- **Strengths**: Captures a large volume of studies (13,243 records), suggesting broad coverage.
- **Weaknesses**: High exclusion rates (90.7% during screening, 40.2% during eligibility) indicate many studies are irrelevant or non-compliant with NLP criteria.
- **Implication**: While comprehensive, this method requires rigorous filtering to ensure quality.
2. **Other Methods (Citation Searching)**:
- **Strengths**: Lower initial volume (52 records) but higher relevance, with only 21.2% exclusion during eligibility.
- **Weaknesses**: Limited scalability due to smaller starting pool.
- **Implication**: This method may yield higher-quality studies but lacks the breadth of database searches.
**Notable Trends**:
- Non-NLP exclusions are more prevalent in the database branch, suggesting stricter adherence to NLP criteria in this pathway.
- Non-relevance exclusions dominate in both branches, emphasizing the importance of topic alignment in study selection.
**Conclusion**: The flowchart underscores the trade-off between quantity (database/registry) and quality (citation searching). Systematic reviewers must balance these factors to ensure comprehensive yet relevant study inclusion.