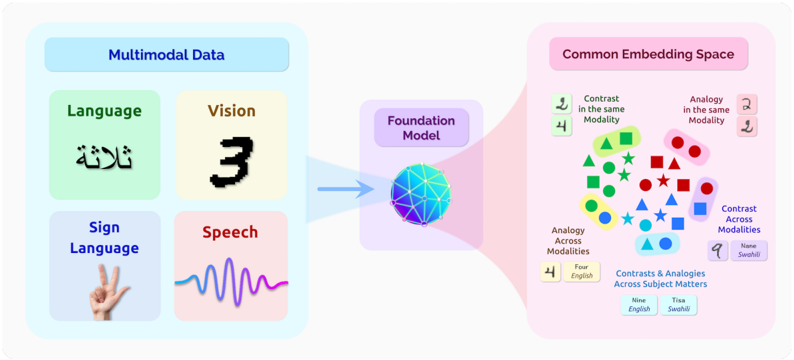
## Diagram: Multimodal Data Integration Architecture
### Overview
The diagram illustrates a multimodal data integration system where diverse data types (language, vision, sign language, speech) are processed through a foundation model to create a common embedding space. The architecture emphasizes relationships between modalities through contrasts and analogies.
### Components/Axes
1. **Multimodal Data Section (Left)**
- **Language**: Green box with Arabic text (لا شيء)
- **Vision**: Yellow box with numeral "3"
- **Sign Language**: Purple box with hand gesture (peace sign)
- **Speech**: Pink box with waveform pattern
- **Connecting Element**: Blue arrow pointing to Foundation Model
2. **Foundation Model (Center)**
- Central sphere with network-like structure
- Positioned between Multimodal Data and Common Embedding Space
3. **Common Embedding Space (Right)**
- Contains geometric shapes with labels:
- **Contrast in the same Modality**: Green triangle
- **Analogy in the same Modality**: Red star
- **Contrast Across Modalities**: Blue triangle
- **Analogy Across Modalities**: Pink square
- **Four English**: Yellow square
- **Nine English**: Blue circle
- **Tisa Swahili**: Pink circle
- Text labels include "Contrasts & Analogies Across Subject Matters"
### Detailed Analysis
- **Multimodal Data Representation**:
- Language: Arabic text (لا شيء) in green
- Vision: Numerical representation (3) in yellow
- Sign Language: Visual gesture (peace sign) in purple
- Speech: Acoustic waveform in pink
- **Embedding Space Relationships**:
- Contrast relationships shown through geometric shapes
- Analogy relationships represented by different symbols
- Cross-subject examples include English (4, 9) and Swahili (Tisa)
### Key Observations
1. The architecture emphasizes bidirectional relationships between modalities
2. Contrast and analogy concepts are central to the integration process
3. Cross-lingual examples (English/Swahili) suggest multilingual capabilities
4. The foundation model acts as a central processing unit for all modalities
### Interpretation
This diagram demonstrates a theoretical framework for multimodal AI systems where:
- Diverse data types are first processed individually (Multimodal Data section)
- A foundation model synthesizes these inputs
- The resulting common embedding space captures both within-modality relationships (contrasts/analogies) and cross-modality relationships
- The inclusion of multiple languages (English/Swahili) indicates potential for cross-lingual understanding
- The geometric representations suggest a mathematical or vector-based approach to modeling relationships
The architecture implies that effective multimodal understanding requires capturing both surface-level contrasts and deeper analogical relationships across different data modalities.