\n
## Bar Chart: Mean Token Length by Correctness
### Overview
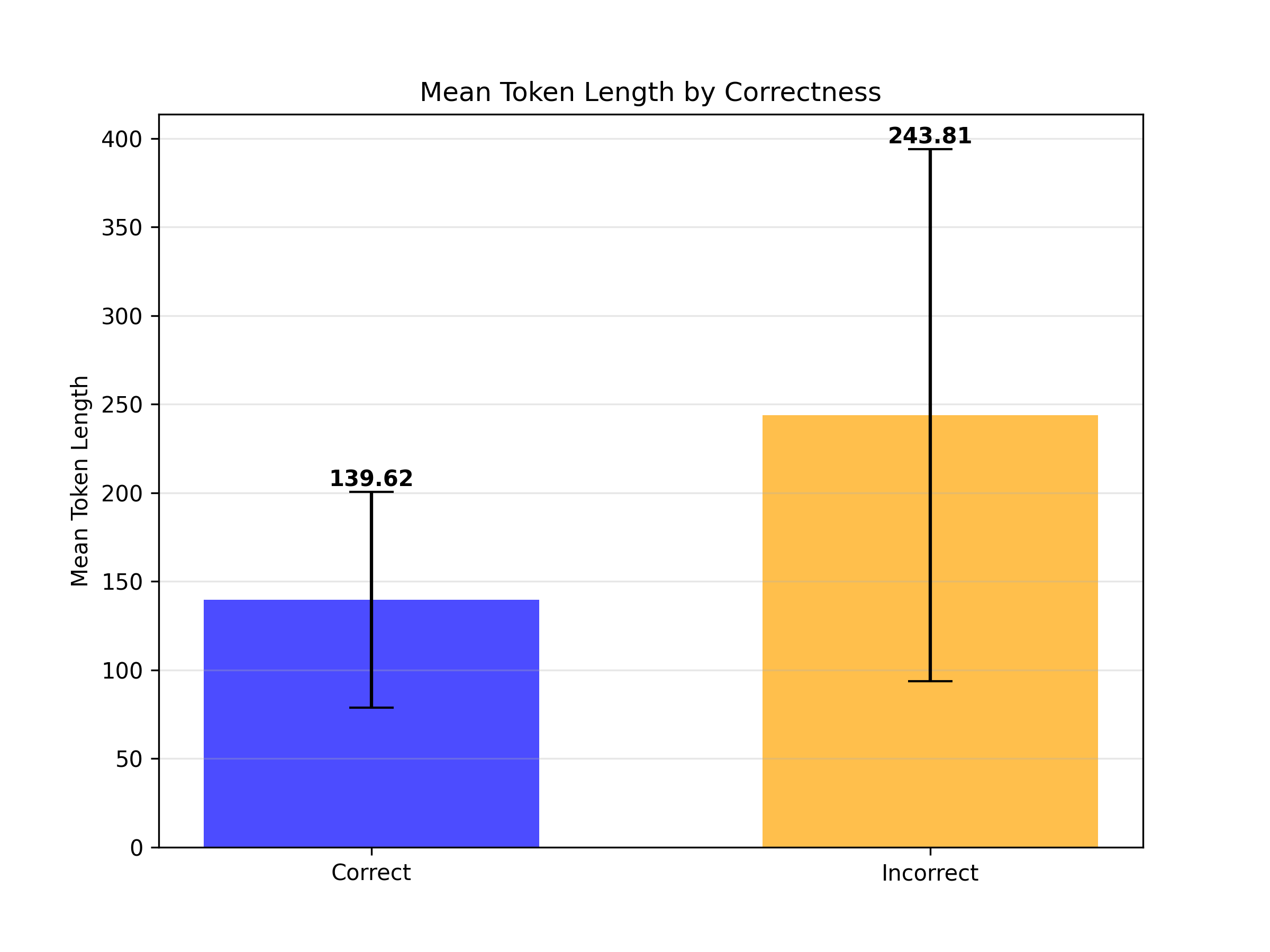
This bar chart visualizes the relationship between the correctness of a token and its mean token length. The chart displays two bars representing "Correct" and "Incorrect" tokens, with error bars indicating the variability in token length for each category.
### Components/Axes
* **Title:** "Mean Token Length by Correctness" (positioned at the top-center)
* **X-axis:** "Correctness" with two categories: "Correct" and "Incorrect".
* **Y-axis:** "Mean Token Length" ranging from 0 to 400, with tick marks at intervals of 50.
* **Bars:** Two bars representing the mean token length for each correctness category.
* "Correct" bar is blue.
* "Incorrect" bar is orange.
* **Error Bars:** Black vertical lines extending above and below each bar, representing the variability (likely standard deviation or standard error) of the mean token length.
* **Data Labels:** Numerical values displayed above each bar, indicating the mean token length.
### Detailed Analysis
* **Correct Tokens:**
* The blue bar for "Correct" tokens has a height corresponding to a mean token length of approximately 139.62.
* The error bar extends from approximately 100 to 180.
* **Incorrect Tokens:**
* The orange bar for "Incorrect" tokens has a height corresponding to a mean token length of approximately 243.81.
* The error bar extends from approximately 200 to 290.
* **Trend:** The mean token length is significantly higher for incorrect tokens compared to correct tokens. The error bars suggest a wider range of token lengths for incorrect tokens.
### Key Observations
* Incorrect tokens have a substantially higher mean token length than correct tokens.
* The variability in token length appears to be greater for incorrect tokens, as indicated by the larger error bar.
* The error bars do not overlap, suggesting a statistically significant difference in mean token length between the two categories.
### Interpretation
The data suggests that longer tokens are more likely to be incorrect. This could be due to several factors:
* **Complexity:** Longer tokens might represent more complex concepts or phrases that are more prone to errors during processing or generation.
* **Noise:** Longer tokens might be more susceptible to noise or errors in the input data.
* **Generation Issues:** If the tokens are generated, a longer token might be the result of a more complex generation process that is more prone to errors.
The significant difference in mean token length and the non-overlapping error bars indicate a strong relationship between token length and correctness. Further investigation is needed to understand the underlying causes of this relationship and to determine whether reducing token length can improve correctness. The error bars provide a measure of the spread of the data, indicating the degree of variability within each category. The wider error bar for incorrect tokens suggests that the relationship between token length and correctness may be more complex for incorrect tokens.