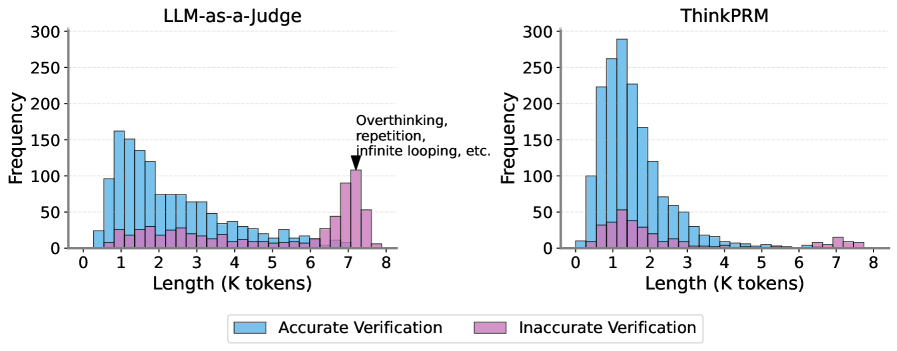
## Bar Charts: LLM-as-a-Judge vs ThinkPRM Verification Frequencies
### Overview
The image contains two side-by-side bar charts comparing verification frequencies for two language model systems: "LLM-as-a-Judge" (left) and "ThinkPRM" (right). Both charts show distributions of response lengths (in thousands of tokens) for accurate vs inaccurate verification outcomes.
### Components/Axes
- **X-axis**: "Length (K tokens)" with discrete bins from 0 to 8
- **Y-axis**: "Frequency" with values from 0 to 300
- **Legends**:
- Blue bars = Accurate Verification
- Pink bars = Inaccurate Verification
- **Chart Labels**:
- Left: "LLM-as-a-Judge"
- Right: "ThinkPRM"
- **Special Annotation**: Arrow pointing to pink bars in LLM-as-a-Judge chart at 7-8K tokens with text: "Overthinking, repetition, infinite looping, etc."
### Detailed Analysis
**LLM-as-a-Judge (Left Chart)**
- **Accurate Verification (Blue)**:
- Peaks at 1K tokens (~150 frequency)
- Gradual decline to ~50 at 3K tokens
- Minimal presence beyond 4K tokens
- **Inaccurate Verification (Pink)**:
- Low frequency (<20) until 6K tokens
- Sharp increase to ~100 at 7K tokens
- Slight drop to ~50 at 8K tokens
- **Key Pattern**: Accurate responses dominate at shorter lengths, while inaccuracies spike dramatically at longer lengths
**ThinkPRM (Right Chart)**
- **Accurate Verification (Blue)**:
- Dominant peak at 1K tokens (~250 frequency)
- Rapid decline to ~50 at 2K tokens
- Near-zero presence beyond 3K tokens
- **Inaccurate Verification (Pink)**:
- Secondary peak at 2K tokens (~50 frequency)
- Sharp drop to <10 at 3K tokens
- Minimal presence beyond 4K tokens
- **Key Pattern**: Strong accuracy at shortest length, with minimal long responses regardless of accuracy
### Key Observations
1. **Length-Accuracy Tradeoff**: Both systems show optimal accuracy at 1K tokens, with performance degrading as response length increases
2. **LLM-as-a-Judge Anomaly**: Unusually high inaccurate verification frequencies at 7-8K tokens (up to 100), suggesting pathological behavior
3. **ThinkPRM Stability**: Maintains near-zero response lengths beyond 3K tokens, avoiding the LLM-as-a-Judge's pathological long responses
4. **Verification Disparity**: LLM-as-a-Judge has 3x more inaccurate verification attempts than ThinkPRM at peak lengths
### Interpretation
The data reveals fundamental differences in how these systems handle verification tasks:
- **LLM-as-a-Judge** demonstrates capacity for longer responses but suffers from catastrophic failure modes at extended lengths, potentially due to recursive self-analysis or infinite reasoning loops
- **ThinkPRM** shows superior stability, completely avoiding long responses that could lead to verification errors
- The 7-8K token spike in LLM-as-a-Judge's inaccurate verification suggests a critical failure mode where the system enters non-terminating reasoning states
- Both systems' optimal performance at 1K tokens implies that concise responses are most reliable for verification tasks, though ThinkPRM's complete absence of long responses may indicate overly restrictive design parameters
The charts highlight an important consideration in LLM design: balancing response length with verification reliability, particularly when systems are used in self-evaluative roles.