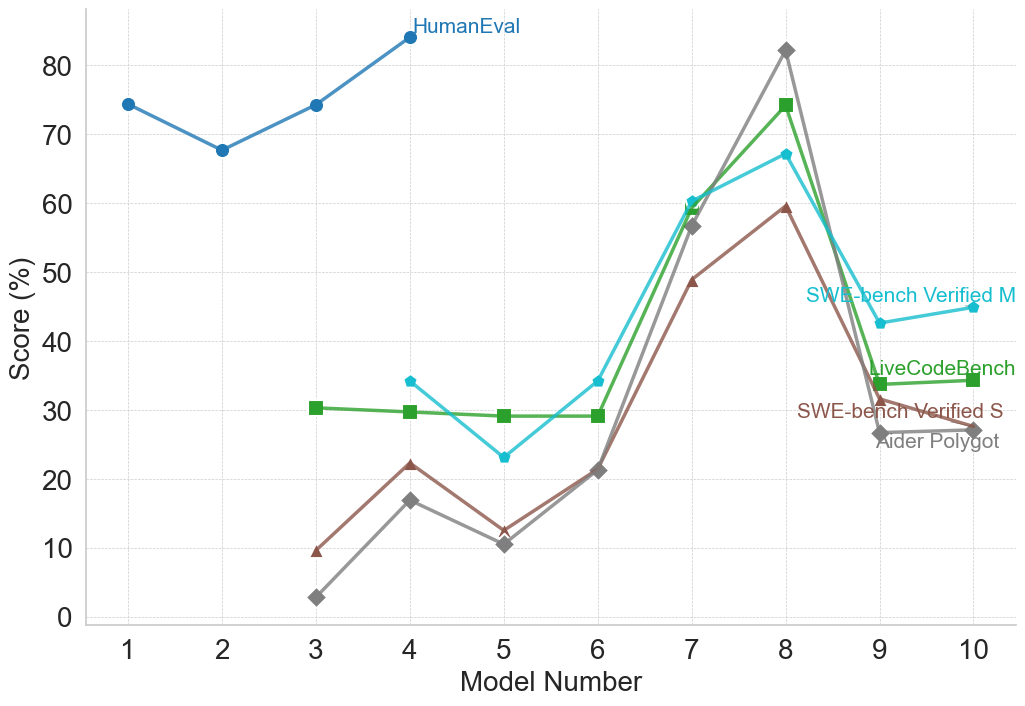
## Line Chart: Model Performance Comparison
### Overview
The image is a line chart comparing the performance of different models (numbered 1 to 10) across several benchmarks: HumanEval, SWE-bench Verified M, LiveCodeBench, SWE-bench Verified S, and Aider Polygot. The y-axis represents the score in percentage (%), and the x-axis represents the model number.
### Components/Axes
* **X-axis:** Model Number (ranging from 1 to 10)
* **Y-axis:** Score (%) (ranging from 0 to 80)
* **Legend (Right Side):**
* HumanEval (Blue)
* SWE-bench Verified M (Cyan)
* LiveCodeBench (Green)
* SWE-bench Verified S (Brown)
* Aider Polygot (Gray)
### Detailed Analysis
* **HumanEval (Blue):** Starts at approximately 75% for Model 1, dips to around 68% for Model 2, then rises to about 74% for Model 3, and continues to increase to approximately 84% for Model 4.
* Model 1: ~75%
* Model 2: ~68%
* Model 3: ~74%
* Model 4: ~84%
* **SWE-bench Verified M (Cyan):** Starts around 34% for Model 4, decreases to approximately 23% for Model 5, increases to about 29% for Model 6, then rises sharply to approximately 57% for Model 7, peaks at approximately 67% for Model 8, and then decreases to approximately 43% for Model 9.
* Model 4: ~34%
* Model 5: ~23%
* Model 6: ~29%
* Model 7: ~57%
* Model 8: ~67%
* Model 9: ~43%
* **LiveCodeBench (Green):** Remains relatively stable around 30% for Models 3 to 6, then increases sharply to approximately 60% for Model 7, peaks at approximately 74% for Model 8, and then decreases to approximately 35% for Model 9.
* Model 3: ~30%
* Model 4: ~30%
* Model 5: ~29%
* Model 6: ~29%
* Model 7: ~60%
* Model 8: ~74%
* Model 9: ~35%
* **SWE-bench Verified S (Brown):** Starts at approximately 9% for Model 3, increases to approximately 22% for Model 4, decreases to approximately 11% for Model 5, increases to approximately 21% for Model 6, rises sharply to approximately 48% for Model 7, peaks at approximately 59% for Model 8.
* Model 3: ~9%
* Model 4: ~22%
* Model 5: ~11%
* Model 6: ~21%
* Model 7: ~48%
* Model 8: ~59%
* **Aider Polygot (Gray):** Starts at approximately 3% for Model 3, increases to approximately 17% for Model 4, decreases to approximately 10% for Model 5, increases to approximately 21% for Model 6, rises sharply to approximately 57% for Model 7, peaks at approximately 82% for Model 8.
* Model 3: ~3%
* Model 4: ~17%
* Model 5: ~10%
* Model 6: ~21%
* Model 7: ~57%
* Model 8: ~82%
### Key Observations
* HumanEval consistently shows high scores across all models, with a generally increasing trend.
* Aider Polygot shows the most significant improvement from Model 3 to Model 8.
* LiveCodeBench and SWE-bench Verified M peak at Model 8 and then decline.
* SWE-bench Verified S shows a similar trend to Aider Polygot but with lower overall scores.
* Models 7 and 8 appear to be the most successful across all benchmarks except HumanEval.
### Interpretation
The chart illustrates the performance of different models on various coding benchmarks. HumanEval appears to be a less sensitive benchmark, as all models perform relatively well. Aider Polygot shows substantial improvement, suggesting that later models have significantly enhanced capabilities in this area. The peak performance of LiveCodeBench and SWE-bench Verified M at Model 8, followed by a decline, could indicate overfitting or specific optimizations that benefited Model 8 but not subsequent models. The data suggests that Model 8 is a strong performer across multiple benchmarks, while HumanEval provides a consistently high baseline.