\n
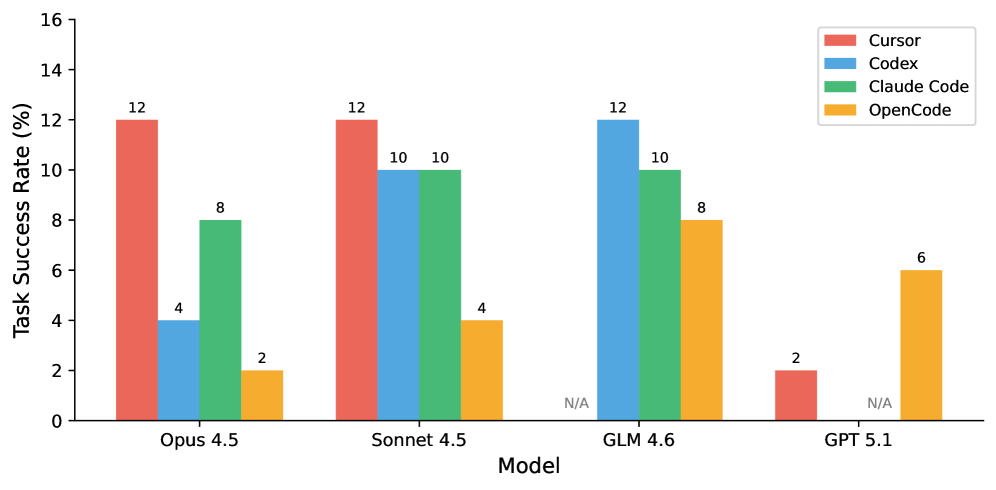
## Bar Chart: Task Success Rate by Model
### Overview
This bar chart compares the task success rates of four different language models – Opus 4.5, Sonnet 4.5, GLM 4.6, and GPT 5.1 – across four different coding approaches: Cursor, Codex, Claude Code, and OpenCode. The success rate is measured as a percentage.
### Components/Axes
* **X-axis:** Model (Opus 4.5, Sonnet 4.5, GLM 4.6, GPT 5.1)
* **Y-axis:** Task Success Rate (%) - Scale ranges from 0 to 16, with increments of 2.
* **Legend:** Located in the top-right corner.
* Cursor (Red)
* Codex (Blue)
* Claude Code (Green)
* OpenCode (Orange)
### Detailed Analysis
The chart consists of four groups of bars, one for each model. Each group contains four bars, representing the task success rate for each coding approach.
* **Opus 4.5:**
* Cursor: Approximately 12%
* Codex: Approximately 4%
* Claude Code: Approximately 8%
* OpenCode: Approximately 2%
* **Sonnet 4.5:**
* Cursor: Approximately 12%
* Codex: Approximately 10%
* Claude Code: Approximately 10%
* OpenCode: Approximately 4%
* **GLM 4.6:**
* Cursor: Approximately 12%
* Codex: Approximately 10%
* Claude Code: Approximately 12%
* OpenCode: N/A (Not Available)
* **GPT 5.1:**
* Cursor: Approximately 2%
* Codex: N/A (Not Available)
* Claude Code: N/A (Not Available)
* OpenCode: Approximately 6%
### Key Observations
* Cursor consistently achieves the highest success rate across Opus 4.5, Sonnet 4.5, and GLM 4.6.
* OpenCode is not available for GLM 4.6 and Codex/Claude Code are not available for GPT 5.1.
* GPT 5.1 has a significantly lower success rate for Cursor compared to other models.
* Codex and Claude Code show similar performance for Opus 4.5 and Sonnet 4.5.
### Interpretation
The data suggests that the Cursor coding approach is generally the most effective across the tested models, except for GPT 5.1 where it performs poorly. The success rates vary significantly between models, indicating that the underlying architecture and training data of each model influence its performance with different coding approaches. The "N/A" values suggest that certain coding approaches were not tested or are not supported by specific models. The relatively low success rate of GPT 5.1 with Cursor could indicate compatibility issues or a need for further optimization of the Cursor approach for this model. The consistent performance of Codex and Claude Code across Opus 4.5 and Sonnet 4.5 suggests a degree of robustness in these approaches. Overall, the chart highlights the importance of selecting the appropriate coding approach and model combination to maximize task success rate.