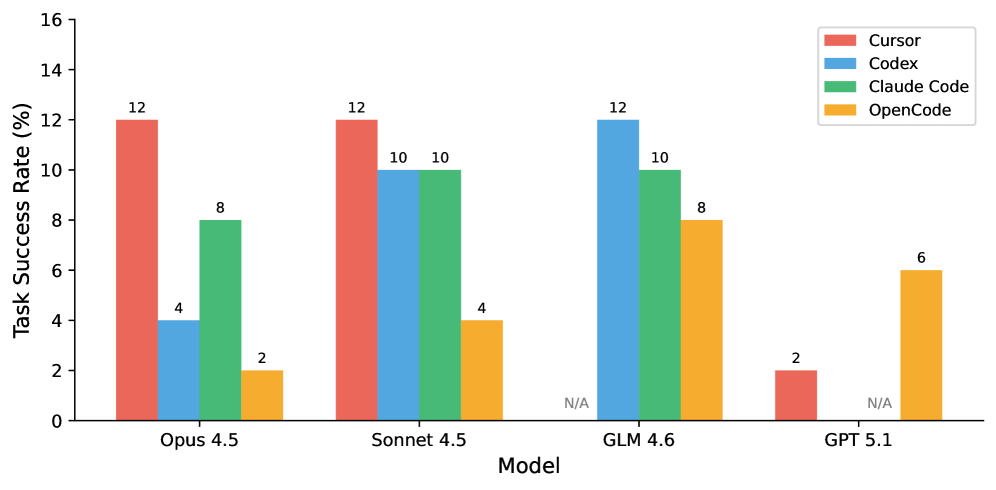
## Grouped Bar Chart: Task Success Rate by Model and Coding Tool
### Overview
This image is a grouped bar chart comparing the "Task Success Rate (%)" of four different AI models (Opus 4.5, Sonnet 4.5, GLM 4.6, GPT 5.1) when used with four distinct coding tools (Cursor, Codex, Claude Code, OpenCode). The chart visualizes performance differences across both models and tools.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **X-Axis (Horizontal):** Labeled "Model". It lists four categorical models:
1. Opus 4.5
2. Sonnet 4.5
3. GLM 4.6
4. GPT 5.1
* **Y-Axis (Vertical):** Labeled "Task Success Rate (%)". It is a linear scale ranging from 0 to 16, with major tick marks at intervals of 2 (0, 2, 4, 6, 8, 10, 12, 14, 16).
* **Legend:** Located in the top-right corner of the chart area. It maps colors to the four coding tools:
* **Red:** Cursor
* **Blue:** Codex
* **Green:** Claude Code
* **Yellow/Orange:** OpenCode
* **Data Labels:** Numerical values are printed directly above most bars, indicating the exact success rate percentage. The label "N/A" is used for missing data points.
### Detailed Analysis
The chart presents the following data points for each model-tool combination. The color of each bar is cross-referenced with the legend.
**1. Model: Opus 4.5**
* **Cursor (Red):** 12%
* **Codex (Blue):** 4%
* **Claude Code (Green):** 8%
* **OpenCode (Yellow):** 2%
**2. Model: Sonnet 4.5**
* **Cursor (Red):** 12%
* **Codex (Blue):** 10%
* **Claude Code (Green):** 10%
* **OpenCode (Yellow):** 4%
**3. Model: GLM 4.6**
* **Cursor (Red):** N/A (No bar present)
* **Codex (Blue):** 12%
* **Claude Code (Green):** 10%
* **OpenCode (Yellow):** 8%
**4. Model: GPT 5.1**
* **Cursor (Red):** 2%
* **Codex (Blue):** N/A (No bar present)
* **Claude Code (Green):** N/A (No bar present)
* **OpenCode (Yellow):** 6%
### Key Observations
* **Highest Performance:** The highest success rate shown is 12%, achieved by three different combinations: Cursor with Opus 4.5, Cursor with Sonnet 4.5, and Codex with GLM 4.6.
* **Tool Consistency:** Cursor shows high variance, performing best with Opus/Sonnet (12%) but worst with GPT (2%) and is not applicable to GLM. OpenCode shows the most consistent, albeit lower, performance across all models (2%, 4%, 8%, 6%).
* **Model Performance:** Sonnet 4.5 and GLM 4.6 show the most consistent high performance across multiple tools. GPT 5.1 shows the lowest overall performance among the models with available data.
* **Missing Data:** There are two "N/A" points: Cursor is not applicable to GLM 4.6, and both Codex and Claude Code are not applicable to GPT 5.1.
### Interpretation
This chart suggests that the effectiveness of a coding assistant is highly dependent on the specific pairing of the underlying AI model and the coding tool interface. There is no single "best" tool or model; performance is contextual.
* **Cursor** appears to be a powerful tool for the Opus and Sonnet model families but is ineffective with GPT 5.1 and incompatible with GLM 4.6 in this test.
* **Codex** performs exceptionally well with GLM 4.6 but poorly with Opus 4.5.
* **Claude Code** delivers solid, middle-of-the-road performance (8-10%) with the three models it was tested on.
* **OpenCode** is a universal but lower-performing option, suggesting it may be a more general-purpose or less specialized tool.
The "N/A" values are critical findings, indicating either a lack of integration between that tool and model or a failure to produce a measurable result in the test scenario. The data implies that users should select their tool based on the specific model they are employing to maximize task success rates.