## Chart: Model Performance vs. Depth
### Overview
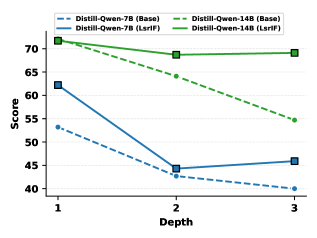
The image is a line chart comparing the performance (Score) of two models, Distill-Qwen-7B and Distill-Qwen-14B, at different depths (1, 2, and 3). Each model has two versions: a "Base" version and an "LsrIF" version. The chart shows how the score changes with depth for each of these versions.
### Components/Axes
* **X-axis:** Depth, with markers at 1, 2, and 3.
* **Y-axis:** Score, ranging from 40 to 70, with gridlines at intervals of 5.
* **Legend (top):**
* Distill-Qwen-7B (Base): Dashed blue line
* Distill-Qwen-7B (LsrIF): Solid blue line
* Distill-Qwen-14B (Base): Dashed green line
* Distill-Qwen-14B (LsrIF): Solid green line
### Detailed Analysis
* **Distill-Qwen-7B (Base):** (Dashed blue line) Starts at approximately 53 at depth 1, decreases to approximately 43 at depth 2, and further decreases to approximately 40 at depth 3.
* **Distill-Qwen-7B (LsrIF):** (Solid blue line) Starts at approximately 62 at depth 1, decreases to approximately 44 at depth 2, and increases slightly to approximately 46 at depth 3.
* **Distill-Qwen-14B (Base):** (Dashed green line) Starts at approximately 72 at depth 1, decreases to approximately 64 at depth 2, and decreases to approximately 55 at depth 3.
* **Distill-Qwen-14B (LsrIF):** (Solid green line) Starts at approximately 72 at depth 1, decreases slightly to approximately 69 at depth 2, and remains approximately at 69 at depth 3.
### Key Observations
* The "LsrIF" versions of both models generally outperform their "Base" counterparts.
* The performance of all models tends to decrease as depth increases, except for Distill-Qwen-7B (LsrIF), which shows a slight increase from depth 2 to depth 3.
* Distill-Qwen-14B models generally outperform Distill-Qwen-7B models.
### Interpretation
The chart suggests that the "LsrIF" modification improves the performance of both Distill-Qwen models. The decrease in performance with increasing depth could indicate that the models are becoming more complex and potentially overfitting, or that the benefits of increased depth are not being fully realized. The Distill-Qwen-14B models consistently outperform the Distill-Qwen-7B models, indicating that the larger model size contributes to better performance. The slight increase in performance for Distill-Qwen-7B (LsrIF) from depth 2 to depth 3 could be an anomaly or indicate a specific interaction between the "LsrIF" modification and depth for this particular model.