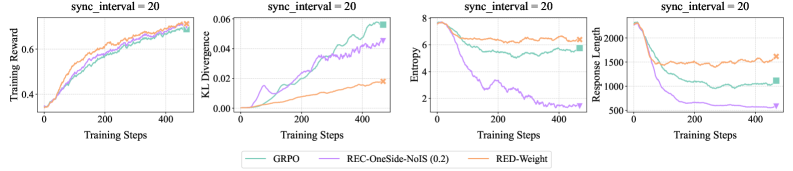
## Line Charts: Training Metrics Comparison
### Overview
The image contains four line charts comparing the performance of three different algorithms (GRPO, REC-OneSide-NoIS (0.2), and RED-Weight) across several training metrics: Training Reward, KL Divergence, Entropy, and Response Length. All charts share a common x-axis representing Training Steps, and each chart has a title indicating "sync_interval = 20".
### Components/Axes
* **Titles (Top of each chart):** "sync\_interval = 20" (repeated for each chart)
* **X-Axis (Shared):** "Training Steps" (range: 0 to 400 approximately)
* **Y-Axis (Left to Right):**
* Chart 1: "Training Reward" (range: 0.4 to 0.6)
* Chart 2: "KL Divergence" (range: 0.00 to 0.06)
* Chart 3: "Entropy" (range: 2 to 8)
* Chart 4: "Response Length" (range: 500 to 2000)
* **Legend (Bottom):**
* GRPO (Teal)
* REC-OneSide-NoIS (0.2) (Purple)
* RED-Weight (Orange)
### Detailed Analysis
**Chart 1: Training Reward**
* **GRPO (Teal):** The line starts around 0.4, increases steadily to approximately 0.6 around step 200, and then plateaus with slight fluctuations.
* **REC-OneSide-NoIS (0.2) (Purple):** Similar to GRPO, it starts around 0.4, increases to approximately 0.58 around step 200, and then plateaus with slight fluctuations.
* **RED-Weight (Orange):** Starts around 0.4, increases to approximately 0.58 around step 200, and then plateaus with slight fluctuations.
**Chart 2: KL Divergence**
* **GRPO (Teal):** Starts near 0.00, increases to approximately 0.06 around step 400.
* **REC-OneSide-NoIS (0.2) (Purple):** Starts near 0.00, increases to approximately 0.04 around step 400, with some fluctuations.
* **RED-Weight (Orange):** Starts near 0.00, increases to approximately 0.01 around step 200, and then plateaus.
**Chart 3: Entropy**
* **GRPO (Teal):** Starts around 8, decreases to approximately 6 around step 200, and then plateaus with slight fluctuations.
* **REC-OneSide-NoIS (0.2) (Purple):** Starts around 8, decreases sharply to approximately 2 around step 200, and then plateaus with slight fluctuations.
* **RED-Weight (Orange):** Starts around 8, decreases to approximately 6.5 around step 200, and then plateaus with slight fluctuations.
**Chart 4: Response Length**
* **GRPO (Teal):** Starts around 2000, decreases to approximately 1750 around step 200, and then plateaus with slight fluctuations.
* **REC-OneSide-NoIS (0.2) (Purple):** Starts around 2000, decreases sharply to approximately 750 around step 200, and then plateaus with slight fluctuations.
* **RED-Weight (Orange):** Starts around 2000, decreases to approximately 2000 around step 200, and then plateaus with slight fluctuations.
### Key Observations
* In the Training Reward chart, all three algorithms converge to similar reward values after approximately 200 training steps.
* In the KL Divergence chart, GRPO shows the highest divergence, while RED-Weight shows the lowest.
* In the Entropy chart, REC-OneSide-NoIS (0.2) shows the most significant decrease in entropy.
* In the Response Length chart, REC-OneSide-NoIS (0.2) shows the most significant decrease in response length.
### Interpretation
The charts provide a comparative analysis of three different algorithms across four key training metrics. The "sync\_interval = 20" suggests that the synchronization interval is a parameter being held constant across all experiments.
* **Training Reward:** All algorithms achieve similar performance in terms of training reward, suggesting they are all effective in learning the task.
* **KL Divergence:** The differences in KL Divergence suggest variations in the exploration strategies of the algorithms. Higher divergence might indicate more exploration.
* **Entropy:** The decrease in entropy indicates that the algorithms are becoming more confident in their actions. REC-OneSide-NoIS (0.2) appears to converge to a more deterministic policy faster.
* **Response Length:** The decrease in response length suggests that the algorithms are learning to generate shorter, more efficient responses. REC-OneSide-NoIS (0.2) achieves the shortest response length.
Overall, the REC-OneSide-NoIS (0.2) algorithm seems to exhibit a more rapid convergence to a deterministic policy with shorter response lengths, while maintaining a comparable training reward. The GRPO algorithm shows a higher KL divergence, suggesting a different exploration strategy.