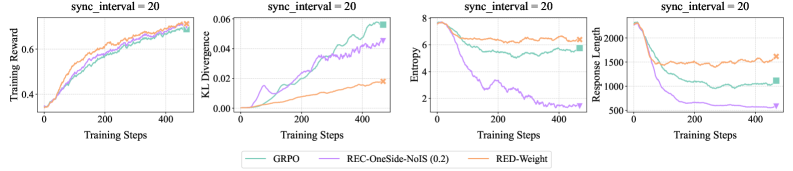
## Line Graphs: Model Performance Metrics Over Training Steps
### Overview
The image contains four line graphs arranged in a 2x2 grid, each tracking different performance metrics (Training Reward, KL Divergence, Entropy, Response Length) for three models (GRPO, REC-OneSide-NoIS, RED-Weight) over 400 training steps. All graphs share a synchronization interval of 20. The y-axes vary by metric, with x-axes uniformly labeled "Training Steps".
### Components/Axes
1. **Top-Left Graph**:
- **Title**: Training Reward
- **Y-Axis**: Training Reward (0.0–0.8)
- **X-Axis**: Training Steps (0–400)
- **Legend**: GRPO (green), REC-OneSide-NoIS (purple), RED-Weight (orange)
2. **Top-Right Graph**:
- **Title**: KL Divergence
- **Y-Axis**: KL Divergence (0.0–0.06)
- **X-Axis**: Training Steps (0–400)
- **Legend**: Same as above
3. **Bottom-Left Graph**:
- **Title**: Entropy
- **Y-Axis**: Entropy (0–8)
- **X-Axis**: Training Steps (0–400)
- **Legend**: Same as above
4. **Bottom-Right Graph**:
- **Title**: Response Length
- **Y-Axis**: Response Length (0–2000)
- **X-Axis**: Training Steps (0–400)
- **Legend**: Same as above
### Detailed Analysis
#### Training Reward (Top-Left)
- **GRPO (green)**: Starts at ~0.3, rises steadily to ~0.75 by 400 steps.
- **REC-OneSide-NoIS (purple)**: Similar trajectory to GRPO, peaking at ~0.72.
- **RED-Weight (orange)**: Slightly lower than the other two, reaching ~0.70.
- **Trend**: All models show consistent improvement, with GRPO and REC-OneSide-NoIS outperforming RED-Weight.
#### KL Divergence (Top-Right)
- **GRPO (green)**: Begins near 0.0, rises to ~0.04 by 400 steps.
- **REC-OneSide-NoIS (purple)**: Peaks at ~0.035 around 200 steps, then declines.
- **RED-Weight (orange)**: Remains below 0.02 throughout.
- **Trend**: RED-Weight maintains the lowest divergence, suggesting better stability.
#### Entropy (Bottom-Left)
- **GRPO (green)**: Drops from ~7 to ~4 by 400 steps.
- **REC-OneSide-NoIS (purple)**: Steep decline from ~7 to ~2.
- **RED-Weight (orange)**: Gradual decrease to ~5.
- **Trend**: REC-OneSide-NoIS achieves the lowest entropy, indicating more efficient decision-making.
#### Response Length (Bottom-Right)
- **GRPO (green)**: Decreases from ~2000 to ~1000.
- **REC-OneSide-NoIS (purple)**: Sharp drop to ~500.
- **RED-Weight (orange)**: Reduces to ~1500.
- **Trend**: REC-OneSide-NoIS has the shortest response length, suggesting computational efficiency.
### Key Observations
1. **Performance Trade-offs**:
- REC-OneSide-NoIS excels in entropy and response length but lags slightly in training reward.
- RED-Weight shows the most stable KL divergence but underperforms in other metrics.
- GRPO balances reward and divergence but has moderate entropy and response length.
2. **Anomalies**:
- REC-OneSide-NoIS’s entropy and response length drop sharply, suggesting a phase transition in training efficiency.
- KL divergence for REC-OneSide-NoIS peaks early, then stabilizes.
### Interpretation
The data suggests that **REC-OneSide-NoIS** prioritizes efficiency (low entropy, short response length) at the cost of slightly lower training reward. **GRPO** offers a balanced performance, while **RED-Weight** sacrifices reward for stability (low KL divergence). The synchronization interval of 20 likely mitigates catastrophic forgetting, as all models show consistent improvement. Notably, REC-OneSide-NoIS’s rapid entropy reduction implies a focus on refining decision boundaries early in training.