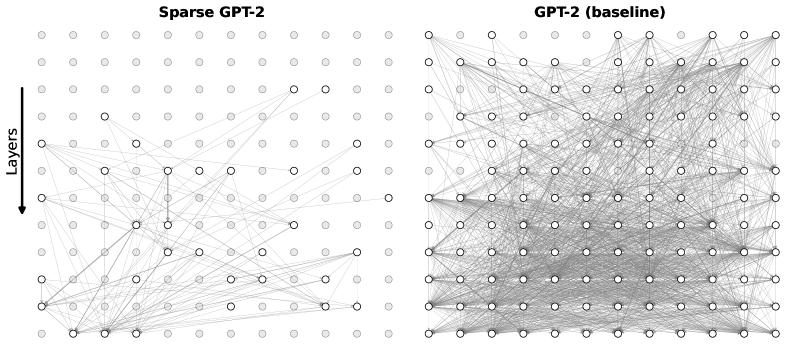
## Network Diagram: Sparse GPT-2 vs. GPT-2 (baseline) Architecture Comparison
### Overview
This image presents a side-by-side visual comparison of two neural network architectures: "Sparse GPT-2" on the left and "GPT-2 (baseline)" on the right. The diagrams use a grid of nodes and connecting lines to illustrate the density of connections (likely representing attention weights or layer-to-layer information flow) within the models. The image starkly contrasts a highly pruned, sparse network with a traditional, fully connected dense network.
### Components/Axes
* **Headers (Top):**
* Left: "Sparse GPT-2"
* Right: "GPT-2 (baseline)"
* **Y-Axis Indicator (Far Left):** A solid black arrow pointing downward, accompanied by the text label "Layers". This establishes the spatial grounding that information flows from the top row (early layers) to the bottom row (late layers).
* **Nodes (Grid Points):** Both diagrams consist of an identical 12x12 grid of circular nodes (144 nodes total per diagram).
* *Light Gray Nodes (No outline):* Represent inactive, pruned, or unconnected components.
* *White Nodes (Black outline):* Represent active components participating in the network's information flow.
* **Edges (Lines):** Thin gray lines connecting the nodes. These represent active pathways, connections, or attention mechanisms between the nodes across different layers.
### Detailed Analysis
**Component Isolation 1: Left Diagram (Sparse GPT-2)**
* **Node Activation:** The vast majority of nodes in this grid are light gray (inactive).
* **Spatial Distribution:**
* *Top Region (Rows 1-3):* Completely devoid of active nodes and connections. All 36 nodes are light gray.
* *Middle Region (Rows 4-7):* Very sparse activation. Row 4 contains only two active nodes (approximate positions: column 8 and 10). A few scattered active nodes appear in rows 5, 6, and 7, with minimal, thin connecting lines.
* *Bottom Region (Rows 8-12):* This is where the majority of the network's activity is concentrated. There is a cluster of active nodes and intersecting lines, particularly weighted toward the bottom-left and bottom-center of the grid.
* **Connection Trend:** The lines form a highly selective, asymmetrical web. Connections frequently skip layers and are heavily localized rather than distributed evenly.
**Component Isolation 2: Right Diagram (GPT-2 baseline)**
* **Node Activation:** Almost every node in the 12x12 grid is white with a black outline (active). Only a tiny fraction (approximately 6-8 nodes scattered primarily in the top 3 rows and far edges) are light gray.
* **Spatial Distribution:** Active nodes are distributed uniformly across the entire grid, from layer 1 down to layer 12.
* **Connection Trend:** The connecting lines form a massive, dense, almost opaque mesh. Every active node appears to be connected to multiple other nodes across various layers. The visual density of the gray lines makes it difficult to trace individual paths, indicating a highly complex, fully interconnected architecture.
### Key Observations
1. **Extreme Density Contrast:** The baseline model exhibits near-total interconnectivity, whereas the sparse model operates on a tiny fraction of those connections.
2. **Early Layer Pruning:** The Sparse GPT-2 model has entirely eliminated connections in the first three layers, suggesting that whatever processing normally occurs there has been bypassed or deemed unnecessary for this specific sparse configuration.
3. **Bottom-Heavy Processing:** The sparse model relies almost entirely on the deeper layers (bottom half of the grid) to route information.
### Interpretation
* **What the data suggests:** This visualization demonstrates the concept of network pruning or sparse attention in Large Language Models (LLMs). The baseline GPT-2 uses a dense attention mechanism where every component (likely attention heads) attends to many others, requiring massive computational power (FLOPs) and memory. The Sparse GPT-2 diagram proves that a model can be heavily pruned—removing the vast majority of its connections—while presumably still functioning.
* **Reading between the lines (Peircean analysis):** The fact that the top layers of the Sparse model are completely inactive is highly significant. In standard LLMs, early layers usually handle basic syntactic and lexical feature extraction, while deeper layers handle complex semantics. The total bypass of early layers here suggests either that the input embeddings are being routed directly to deeper layers, or that this specific sparse model has been optimized for a task where early-layer feature extraction is redundant.
* **Why it matters:** This image visually justifies the pursuit of sparse models. The dense web on the right represents high latency and high hardware requirements. The sparse web on the left represents a highly efficient, compressed model that would run significantly faster and require less memory, highlighting the inherent over-parameterization present in baseline foundational models.