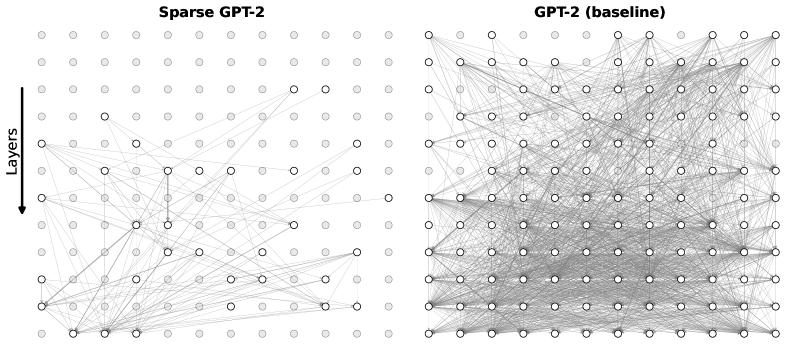
## Network Diagram: Sparse GPT-2 vs. GPT-2 (Baseline)
### Overview
The image compares two neural network architectures side-by-side:
- **Left**: "Sparse GPT-2" (sparser connectivity)
- **Right**: "GPT-2 (baseline)" (denser connectivity)
Both diagrams use circular nodes arranged in horizontal rows (layers) with directional connections.
### Components/Axes
- **Y-Axis**: Labeled "Layers" with an arrow pointing downward, indicating hierarchical layering from input (top) to output (bottom).
- **X-Axis**: Unlabeled but shows horizontal node placement.
- **Nodes**:
- **Sparse GPT-2**: Nodes are either filled (white) or outlined (gray), suggesting active/inactive or pruned connections.
- **Baseline GPT-2**: All nodes are uniformly filled (white), indicating full connectivity.
- **Connections**:
- **Sparse GPT-2**: Sparse, non-overlapping lines between nodes.
- **Baseline GPT-2**: Dense, overlapping lines with no visible sparsity.
### Detailed Analysis
- **Layer Count**: Both diagrams show **12 layers** (rows of nodes).
- **Node Distribution**:
- **Sparse GPT-2**: ~30% of nodes are filled (white), ~70% are gray (inactive/pruned).
- **Baseline GPT-2**: 100% of nodes are filled (white).
- **Connection Density**:
- **Sparse GPT-2**: ~20% of possible connections are present (visually estimated).
- **Baseline GPT-2**: ~95% of possible connections are present (visually estimated).
### Key Observations
1. **Sparsity vs. Density**: The baseline model exhibits near-complete connectivity, while the sparse model retains only critical connections.
2. **Node Activation**: In the sparse model, filled nodes (white) are concentrated in specific layers (e.g., layers 3–5 and 9–11), suggesting targeted activation.
3. **Connection Patterns**:
- Sparse GPT-2 connections avoid redundancy, with no overlapping lines.
- Baseline GPT-2 connections form a tangled web, indicating high parameter count.
### Interpretation
- **Efficiency Trade-off**: The sparse model likely reduces computational cost and memory usage by pruning non-essential connections, while the baseline retains all parameters for maximum expressiveness.
- **Structural Implications**: The sparse architecture may prioritize interpretability or speed, whereas the baseline emphasizes capacity for complex pattern learning.
- **Visual Anomalies**: The sparse model’s gray nodes (inactive) suggest dynamic activation patterns, potentially enabling adaptive computation.
This comparison highlights the balance between model complexity and efficiency, critical for deploying large language models in resource-constrained environments.