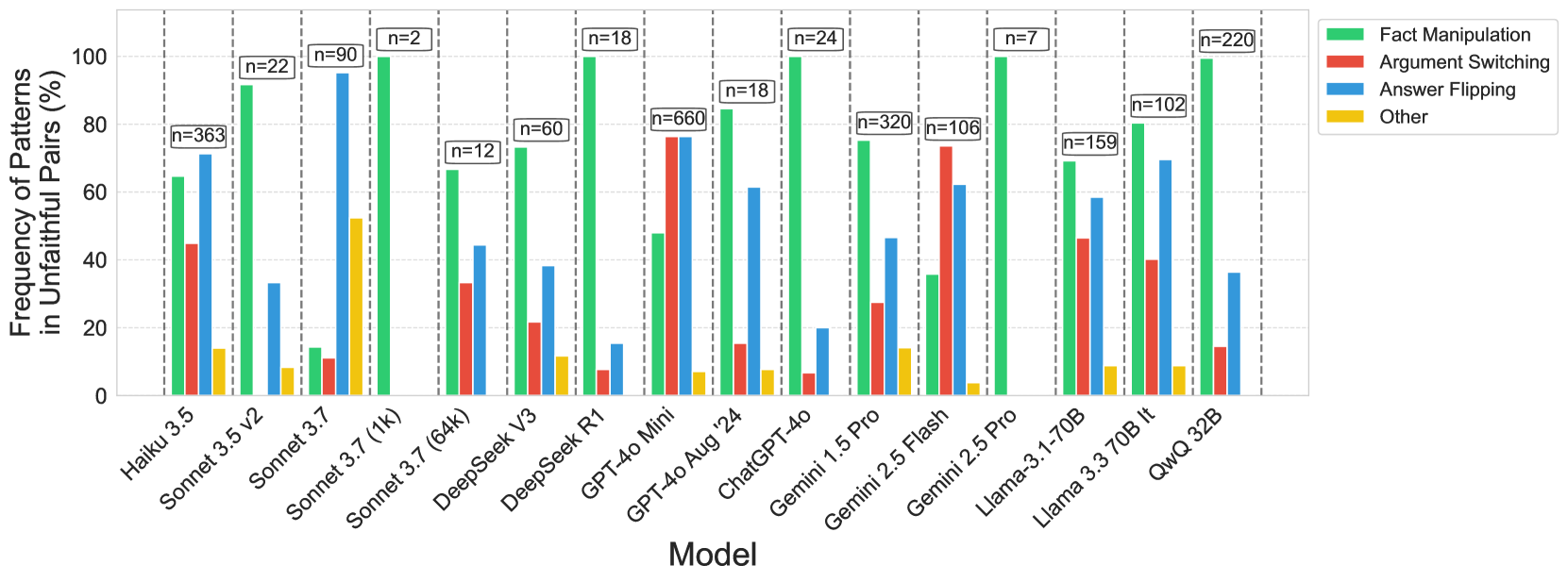
## Bar Chart: Frequency of Patterns in Unfaithful Pairs by Model
### Overview
The image is a bar chart comparing the frequency of different patterns (Fact Manipulation, Argument Switching, Answer Flipping, and Other) in unfaithful pairs across various language models. The y-axis represents the frequency of patterns in unfaithful pairs, measured in percentage, ranging from 0 to 100. The x-axis lists the different language models. Each model has four bars representing the four patterns. The chart also includes the number of samples (n) used for each model, displayed above the bars.
### Components/Axes
* **Y-axis:** "Frequency of Patterns in Unfaithful Pairs (%)", ranging from 0 to 100 in increments of 20.
* **X-axis:** "Model", listing the following models: Haiku 3.5, Sonnet 3.5 v2, Sonnet 3.7, Sonnet 3.7 (1k), Sonnet 3.7 (64k), DeepSeek V3, DeepSeek R1, GPT-4o Mini, GPT-4o Aug '24, ChatGPT-4o, Gemini 1.5 Pro, Gemini 2.5 Flash, Gemini 2.5 Pro, Llama-3.1-70B, Llama 3.3 70B It, QwQ 32B.
* **Legend:** Located on the top-right of the chart.
* Green: Fact Manipulation
* Red: Argument Switching
* Blue: Answer Flipping
* Yellow: Other
* **Sample Sizes (n):** Displayed above each model's bar group.
* Haiku 3.5: n=363
* Sonnet 3.5 v2: n=22
* Sonnet 3.7: n=90
* Sonnet 3.7 (1k): n=2
* Sonnet 3.7 (64k): n=12
* DeepSeek V3: n=60
* DeepSeek R1: n=18
* GPT-4o Mini: n=660
* GPT-4o Aug '24: n=18
* ChatGPT-4o: n=24
* Gemini 1.5 Pro: n=320
* Gemini 2.5 Flash: n=106
* Gemini 2.5 Pro: n=7
* Llama-3.1-70B: n=159
* Llama 3.3 70B It: n=102
* QwQ 32B: n=220
### Detailed Analysis
Here's a breakdown of the approximate values for each model and pattern:
* **Haiku 3.5:**
* Fact Manipulation (Green): ~65%
* Argument Switching (Red): ~45%
* Answer Flipping (Blue): ~75%
* Other (Yellow): ~10%
* **Sonnet 3.5 v2:**
* Fact Manipulation (Green): ~90%
* Argument Switching (Red): ~5%
* Answer Flipping (Blue): ~35%
* Other (Yellow): ~10%
* **Sonnet 3.7:**
* Fact Manipulation (Green): ~95%
* Argument Switching (Red): ~10%
* Answer Flipping (Blue): ~5%
* Other (Yellow): ~50%
* **Sonnet 3.7 (1k):**
* Fact Manipulation (Green): ~95%
* Argument Switching (Red): ~10%
* Answer Flipping (Blue): ~5%
* Other (Yellow): ~50%
* **Sonnet 3.7 (64k):**
* Fact Manipulation (Green): ~15%
* Argument Switching (Red): ~20%
* Answer Flipping (Blue): ~30%
* Other (Yellow): ~10%
* **DeepSeek V3:**
* Fact Manipulation (Green): ~60%
* Argument Switching (Red): ~15%
* Answer Flipping (Blue): ~30%
* Other (Yellow): ~15%
* **DeepSeek R1:**
* Fact Manipulation (Green): ~80%
* Argument Switching (Red): ~10%
* Answer Flipping (Blue): ~5%
* Other (Yellow): ~10%
* **GPT-4o Mini:**
* Fact Manipulation (Green): ~95%
* Argument Switching (Red): ~80%
* Answer Flipping (Blue): ~10%
* Other (Yellow): ~5%
* **GPT-4o Aug '24:**
* Fact Manipulation (Green): ~60%
* Argument Switching (Red): ~80%
* Answer Flipping (Blue): ~40%
* Other (Yellow): ~10%
* **ChatGPT-4o:**
* Fact Manipulation (Green): ~90%
* Argument Switching (Red): ~60%
* Answer Flipping (Blue): ~45%
* Other (Yellow): ~5%
* **Gemini 1.5 Pro:**
* Fact Manipulation (Green): ~60%
* Argument Switching (Red): ~80%
* Answer Flipping (Blue): ~30%
* Other (Yellow): ~10%
* **Gemini 2.5 Flash:**
* Fact Manipulation (Green): ~100%
* Argument Switching (Red): ~75%
* Answer Flipping (Blue): ~30%
* Other (Yellow): ~5%
* **Gemini 2.5 Pro:**
* Fact Manipulation (Green): ~100%
* Argument Switching (Red): ~75%
* Answer Flipping (Blue): ~30%
* Other (Yellow): ~5%
* **Llama-3.1-70B:**
* Fact Manipulation (Green): ~100%
* Argument Switching (Red): ~40%
* Answer Flipping (Blue): ~60%
* Other (Yellow): ~5%
* **Llama 3.3 70B It:**
* Fact Manipulation (Green): ~80%
* Argument Switching (Red): ~50%
* Answer Flipping (Blue): ~60%
* Other (Yellow): ~10%
* **QwQ 32B:**
* Fact Manipulation (Green): ~100%
* Argument Switching (Red): ~10%
* Answer Flipping (Blue): ~35%
* Other (Yellow): ~10%
### Key Observations
* Fact Manipulation (Green) is generally high across most models, often being the most frequent pattern.
* Argument Switching (Red) varies significantly across models, with some models showing high frequencies (e.g., GPT-4o Mini, GPT-4o Aug '24, Gemini 1.5 Pro, Gemini 2.5 Flash, Gemini 2.5 Pro) and others showing low frequencies.
* Answer Flipping (Blue) also varies, but generally lower than Fact Manipulation.
* The "Other" category (Yellow) consistently has the lowest frequency across all models.
* The sample sizes (n) vary significantly across models, which could influence the observed frequencies.
### Interpretation
The bar chart provides a comparative analysis of different types of "unfaithful" behaviors exhibited by various language models. The high frequency of Fact Manipulation across many models suggests a common tendency to generate inaccurate or misleading information. The variability in Argument Switching and Answer Flipping indicates that different models have different strengths and weaknesses in maintaining consistency and coherence. The "Other" category being consistently low suggests that the primary types of unfaithful behaviors are well-captured by the other three categories.
The sample sizes (n) are important to consider when interpreting the results. Models with smaller sample sizes may have less reliable frequency estimates. For example, Sonnet 3.7 (1k) and Gemini 2.5 Pro have very small sample sizes (n=2 and n=7, respectively), so their observed frequencies may not be representative of their overall behavior.
Overall, the chart highlights the challenges in ensuring the reliability and trustworthiness of language models, and the need for ongoing research and development to mitigate these issues.