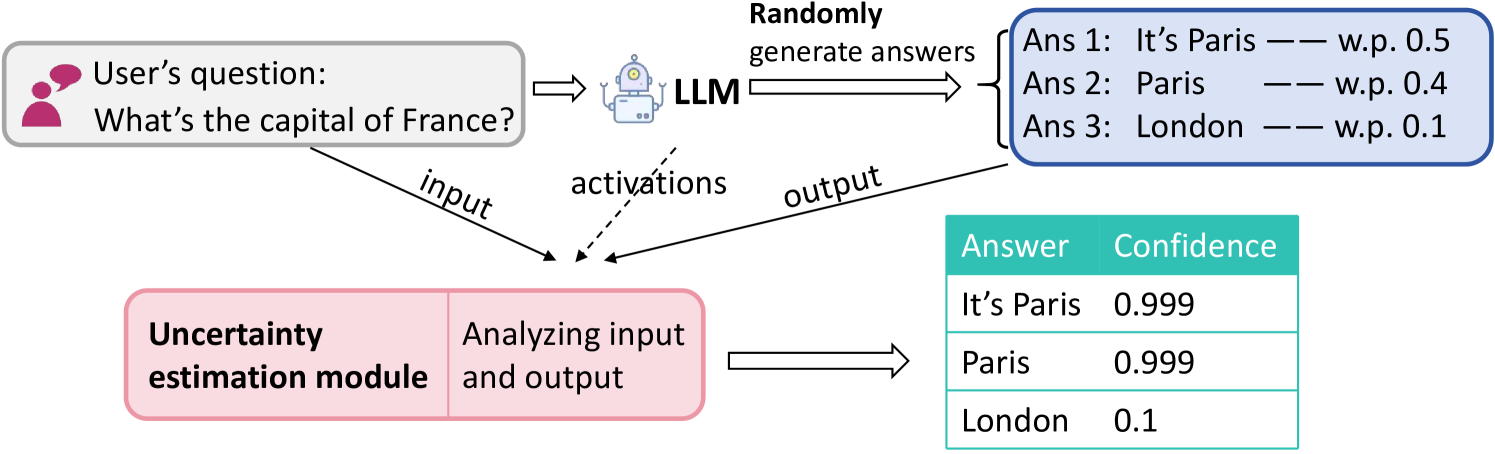
## Flowchart: LLM Answer Generation with Uncertainty Estimation
### Overview
The diagram illustrates a system where a user's question ("What's the capital of France?") is processed by a Large Language Model (LLM) to generate answers. An uncertainty estimation module analyzes the input and output to assign confidence scores to the generated answers. The LLM produces three answers with associated probabilities, while the uncertainty module provides confidence scores for each answer.
### Components/Axes
1. **User Input**:
- Text box labeled "User's question: What's the capital of France?" with a speech bubble icon.
2. **LLM Processing**:
- Labeled "LLM" with a robot icon.
- Outputs three answers with probabilities (w.p.):
- Ans 1: "It's Paris" — w.p. 0.5
- Ans 2: "Paris" — w.p. 0.4
- Ans 3: "London" — w.p. 0.1
3. **Uncertainty Estimation Module**:
- Labeled "Uncertainty estimation module" with a pink background.
- Analyzes input and output to generate confidence scores.
4. **Output Table**:
- Header: "Answer" (green) and "Confidence" (white).
- Rows:
- "It's Paris" — 0.999
- "Paris" — 0.999
- "London" — 0.1
### Detailed Analysis
- **LLM Outputs**:
- The LLM generates three answers with decreasing probabilities. "It's Paris" has the highest probability (0.5), followed by "Paris" (0.4), and "London" (0.1).
- **Uncertainty Module Confidence Scores**:
- The uncertainty module assigns confidence scores to the answers. "It's Paris" and "Paris" both receive the highest confidence (0.999), while "London" has the lowest (0.1).
- **Spatial Relationships**:
- The user's question is positioned at the top-left, connected to the LLM.
- The LLM's output branches into the three answers, which are linked to the uncertainty module.
- The data table is placed on the right, summarizing answers and confidence scores.
### Key Observations
- **High Confidence for Paris**: Both "It's Paris" and "Paris" have near-maximum confidence scores (0.999), indicating strong agreement between the LLM and uncertainty module.
- **Low Confidence for London**: The answer "London" has a confidence score of 0.1, reflecting its low probability (0.1) and high uncertainty.
- **Redundancy in Answers**: "It's Paris" and "Paris" are semantically similar but differ in phrasing, yet both receive identical confidence scores.
### Interpretation
The system demonstrates how uncertainty estimation modules can refine LLM outputs by quantifying confidence in generated answers. The high confidence for Paris-related answers aligns with their higher probabilities, while the low confidence for London highlights its improbability. The uncertainty module effectively filters out less likely answers, ensuring reliability in the final output. This workflow is critical for applications requiring high-accuracy responses, such as educational tools or factual Q&A systems.