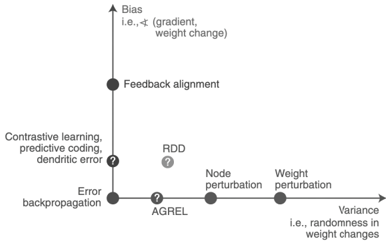
## Bias vs. Variance Plot for Learning Algorithms
### Overview
The image is a 2D scatter plot illustrating the relationship between bias and variance for different learning algorithms. The x-axis represents variance (randomness in weight changes), and the y-axis represents bias (gradient, weight change). Several algorithms are positioned on the plot based on their relative bias and variance.
### Components/Axes
* **X-axis:** Variance, i.e., randomness in weight changes. The axis increases from left to right.
* **Y-axis:** Bias, i.e., gradient, weight change. The axis increases from bottom to top.
* **Data Points:** Represent different learning algorithms.
### Detailed Analysis
The following algorithms are plotted:
* **Error backpropagation:** Located at the origin (bottom-left corner), indicating low bias and low variance.
* **Contrastive learning, predictive coding, dendritic error:** Located on the y-axis, above error backpropagation, indicating low variance and moderate bias. There is a question mark next to this label.
* **Feedback alignment:** Located on the y-axis, higher than the previous point, indicating low variance and high bias.
* **AGREL:** Located on the x-axis, to the right of the origin, indicating low bias and moderate variance. There is a question mark next to this label.
* **Node perturbation:** Located on the x-axis, further to the right than AGREL, indicating low bias and higher variance.
* **Weight perturbation:** Located on the x-axis, furthest to the right, indicating low bias and the highest variance among the plotted algorithms.
* **RDD:** Located in the upper-right quadrant, indicating moderate bias and moderate variance. There is a question mark next to this label.
### Key Observations
* Algorithms on the y-axis (Error backpropagation, Contrastive learning, Feedback alignment) have low variance.
* Algorithms on the x-axis (Error backpropagation, AGREL, Node perturbation, Weight perturbation) have low bias.
* The plot suggests a trade-off between bias and variance.
### Interpretation
The plot visually represents the bias-variance trade-off in machine learning. Algorithms like "Error backpropagation" aim for both low bias and low variance, while others prioritize one over the other. "Feedback alignment" exhibits high bias and low variance, potentially indicating underfitting. "Weight perturbation" exhibits low bias and high variance, potentially indicating overfitting. The question marks next to "Contrastive learning, predictive coding, dendritic error", "AGREL", and "RDD" suggest uncertainty or variability in their exact placement on the bias-variance spectrum. The plot helps in understanding the characteristics of different learning algorithms in terms of their bias and variance properties.