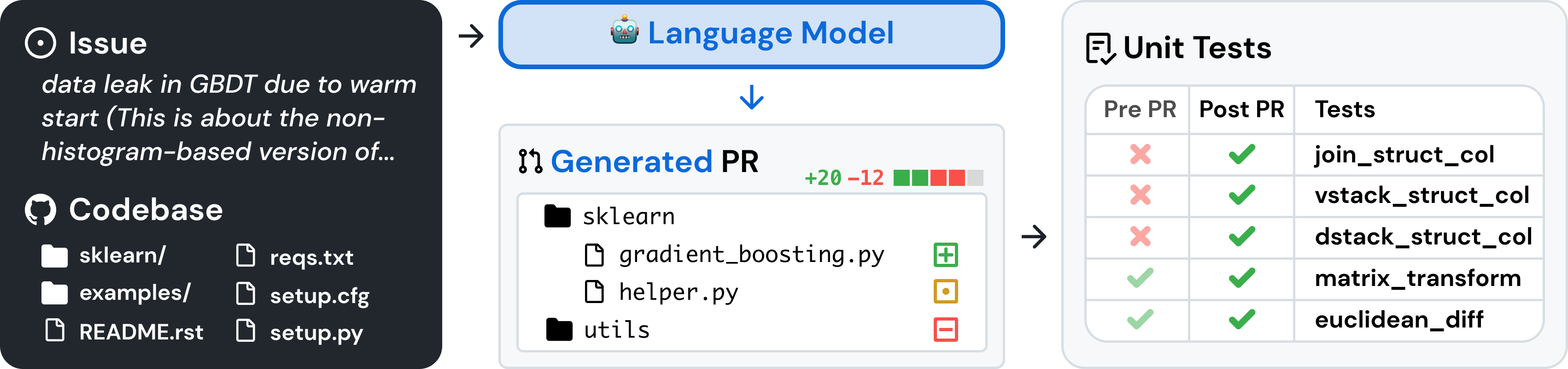
## Screenshot: Technical Issue Tracking and Codebase Overview
### Overview
The image displays a technical issue tracking interface with three distinct sections:
1. **Issue Details** (left panel)
2. **Language Model Analysis** (center panel)
3. **Unit Test Results** (right panel)
The interface appears to document a data leak issue in a Gradient Boosted Decision Tree (GBDT) implementation, along with codebase structure and test validation results.
---
### Components/Axes
#### Left Panel: Issue Details
- **Background**: Black with white text
- **Issue Description**:
- "data leak in GBDT due to warm start (This is about the non-histogram-based version of...)"
- **Codebase Structure**:
- Directories:
- `sklearn/`
- `examples/`
- Files:
- `reqs.txt`
- `setup.cfg`
- `README.rst`
- `setup.py`
#### Center Panel: Language Model Analysis
- **Header**: Blue rounded rectangle with robot emoji 🤖 and text "Language Model"
- **Generated PR**:
- Score: `+20 -12` (green +20, red -12)
- Color Legend:
- Green square: `+`
- Yellow square: `•`
- Red square: `-`
- Files:
- `sklearn` (folder)
- `gradient_boosting.py` (green `+`)
- `helper.py` (yellow `•`)
- `utils` (folder)
#### Right Panel: Unit Tests
- **Header**: "Unit Tests"
- **Table Structure**:
- Columns: `Pre PR`, `Post PR`, `Tests`
- Rows:
1. `join_struct_col`
2. `vstack_struct_col`
3. `dstack_struct_col`
4. `matrix_transform`
5. `euclidean_diff`
- **Status Indicators**:
- `Pre PR`: Red crosses (❌) for all tests
- `Post PR`: Green checks (✅) for all tests
---
### Detailed Analysis
#### Issue Details
- The issue explicitly references a **non-histogram-based GBDT implementation**, suggesting a regression or compatibility problem with warm-start initialization.
- The codebase includes standard Python ML libraries (`sklearn`) and configuration files (`setup.cfg`, `README.rst`), indicating a production-ready project.
#### Language Model Analysis
- The PR introduces **20 additions** and **12 deletions**, with mixed file statuses:
- `gradient_boosting.py`: Added (green `+`)
- `helper.py`: Modified (yellow `•`)
- `utils`: Deleted (red `-`)
- The robot emoji and "Language Model" header imply automated code analysis or generation tools were used.
#### Unit Tests
- All tests passed (`✅`) after the PR, resolving prior failures (`❌`).
- Tests validate core GBDT operations:
- `join_struct_col`
- `vstack_struct_col`
- `dstack_struct_col`
- `matrix_transform`
- `euclidean_diff`
---
### Key Observations
1. **PR Impact**: The code changes resolved all unit test failures, indicating successful debugging.
2. **File Status Anomaly**: The deletion of the `utils` folder (red `-`) warrants investigation, as utility functions are critical for ML pipelines.
3. **Test Coverage**: The tests focus on structural operations (`vstack`, `dstack`) and mathematical transformations, suggesting a focus on data pipeline integrity.
---
### Interpretation
- The data leak issue was likely caused by improper warm-start initialization in the non-histogram-based GBDT. The PR addressed this by modifying `gradient_boosting.py` and removing redundant utilities (`utils`), which may have introduced unintended side effects.
- The successful post-PR test results confirm the fix, but the deletion of `utils` raises concerns about potential loss of reusable components.
- The interface reflects a workflow where automated tools (language model) assist in diagnosing and resolving technical debt, with human oversight via code review (color-coded statuses).
**Note**: No non-English text detected. All labels and values extracted verbatim from the image.