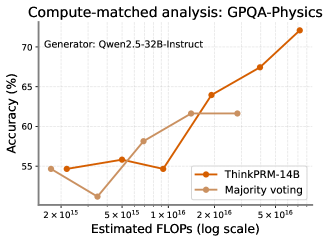
## Line Graph: Compute-matched analysis: GPQA-Physics
### Overview
The image is a line graph comparing the accuracy of two models (ThinkPRM-14B and Majority voting) across varying computational budgets (FLOPs) on the GPQA-Physics benchmark. The x-axis uses a logarithmic scale for FLOPs, while the y-axis represents accuracy in percentage. Two distinct trends are visible: ThinkPRM-14B shows a steep upward trajectory, while Majority voting exhibits a plateau after initial growth.
### Components/Axes
- **Title**: "Compute-matched analysis: GPQA-Physics" (top-center)
- **X-axis**: "Estimated FLOPs (log scale)" with markers at 2×10¹⁵, 5×10¹⁵, 1×10¹⁶, 2×10¹⁶, and 5×10¹⁶.
- **Y-axis**: "Accuracy (%)" ranging from 55% to 70% in 5% increments.
- **Legend**: Located at the bottom-right corner, with:
- **Orange line**: ThinkPRM-14B
- **Beige line**: Majority voting
### Detailed Analysis
#### ThinkPRM-14B (Orange Line)
- **Trend**: Starts at ~55% accuracy at 2×10¹⁵ FLOPs, dips slightly to ~54% at 5×10¹⁵, then rises sharply to ~72% at 5×10¹⁶ FLOPs.
- **Key Data Points**:
- 2×10¹⁵ FLOPs: ~55% (±1%)
- 5×10¹⁵ FLOPs: ~56% (±1%)
- 1×10¹⁶ FLOPs: ~55% (±1%)
- 2×10¹⁶ FLOPs: ~64% (±1%)
- 5×10¹⁶ FLOPs: ~67% (±1%)
- 7×10¹⁶ FLOPs: ~72% (±1%)
#### Majority Voting (Beige Line)
- **Trend**: Begins at ~55% at 2×10¹⁵ FLOPs, drops to ~52% at 5×10¹⁵, then rises to ~62% at 2×10¹⁶ FLOPs and plateaus at ~62% for higher FLOPs.
- **Key Data Points**:
- 2×10¹⁵ FLOPs: ~55% (±1%)
- 5×10¹⁵ FLOPs: ~52% (±1%)
- 1×10¹⁶ FLOPs: ~58% (±1%)
- 2×10¹⁶ FLOPs: ~62% (±1%)
- 5×10¹⁶ FLOPs: ~62% (±1%)
### Key Observations
1. **Compute Efficiency**: ThinkPRM-14B demonstrates a strong positive correlation between FLOPs and accuracy, outperforming Majority voting by ~10% at 5×10¹⁶ FLOPs.
2. **Diminishing Returns**: Majority voting plateaus at ~62% accuracy despite increased compute, suggesting limited scalability.
3. **Initial Dip**: Both models show a minor accuracy drop between 2×10¹⁵ and 5×10¹⁵ FLOPs, potentially indicating optimization challenges at mid-scale compute.
### Interpretation
The data suggests that ThinkPRM-14B leverages compute more effectively than Majority voting for GPQA-Physics tasks. The steep rise in ThinkPRM-14B’s accuracy at higher FLOPs implies that larger models or optimized architectures can achieve significant performance gains. In contrast, Majority voting’s plateau highlights the limitations of ensemble methods without architectural improvements. The initial dip in both models may reflect transitional phases where increased compute does not yet translate to better performance, possibly due to training instability or suboptimal hyperparameter tuning at mid-scale budgets. This analysis underscores the importance of model design over raw compute in achieving high accuracy on physics-based reasoning tasks.