\n
## Bar Chart: Model Accuracy Comparison
### Overview
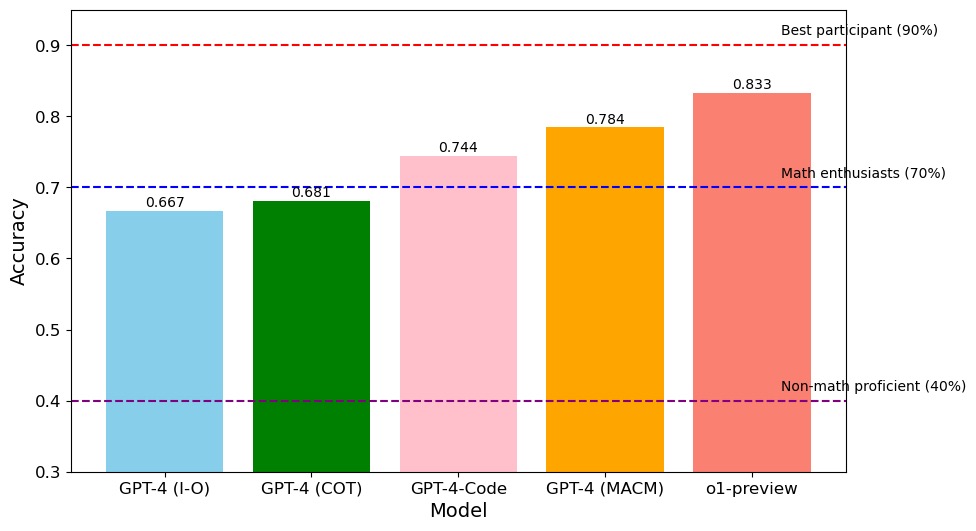
This bar chart compares the accuracy of five different models: GPT-4 (I-O), GPT-4 (COT), GPT-4-Code, GPT-4 (MACM), and ol-preview. Accuracy is measured on a scale from 0.3 to 0.9. Horizontal dashed lines indicate accuracy levels corresponding to "Non-math proficient" (40%), "Math enthusiasts" (70%), and "Best participant" (90%).
### Components/Axes
* **X-axis:** Model - GPT-4 (I-O), GPT-4 (COT), GPT-4-Code, GPT-4 (MACM), ol-preview
* **Y-axis:** Accuracy - Scale from 0.3 to 0.9, with increments of 0.1.
* **Horizontal Lines:**
* 0.4 (labeled "Non-math proficient (40%)") - Dashed blue line.
* 0.7 (labeled "Math enthusiasts (70%)") - Dashed purple line.
* 0.9 (labeled "Best participant (90%)") - Dashed red line.
* **Bars:** Each model is represented by a colored bar, with height corresponding to its accuracy.
### Detailed Analysis
* **GPT-4 (I-O):** The bar is light blue and reaches approximately 0.667 accuracy.
* **GPT-4 (COT):** The bar is green and reaches approximately 0.681 accuracy.
* **GPT-4-Code:** The bar is light pink and reaches approximately 0.744 accuracy.
* **GPT-4 (MACM):** The bar is orange and reaches approximately 0.784 accuracy.
* **ol-preview:** The bar is red and reaches approximately 0.833 accuracy.
The bars generally increase in height from left to right, indicating a trend of increasing accuracy across the models.
### Key Observations
* ol-preview demonstrates the highest accuracy, exceeding the "Best participant" benchmark of 0.9.
* GPT-4 (I-O) has the lowest accuracy among the models tested.
* The accuracy of GPT-4 (COT) is only slightly higher than GPT-4 (I-O).
* GPT-4-Code shows a significant improvement in accuracy compared to the first two models.
* GPT-4 (MACM) continues the trend of increasing accuracy.
### Interpretation
The data suggests that the model architecture and training methodology significantly impact accuracy. The ol-preview model outperforms all others, potentially due to a more advanced architecture or a larger, more diverse training dataset. The progression from GPT-4 (I-O) to GPT-4 (MACM) indicates that incorporating techniques like Chain-of-Thought (COT) and MACM (likely a more complex reasoning method) improves performance. The relatively low accuracy of GPT-4 (I-O) and GPT-4 (COT) suggests that these models struggle with the specific task or dataset used for evaluation. The horizontal lines provide context by relating the model accuracies to human performance levels. The gap between the best model (ol-preview) and the "Best participant" line suggests that the model is exceeding human-level performance on this task. The consistent increase in accuracy across the models suggests a clear path for improvement through architectural and training enhancements.