## Bar Chart: Model Accuracy Comparison
### Overview
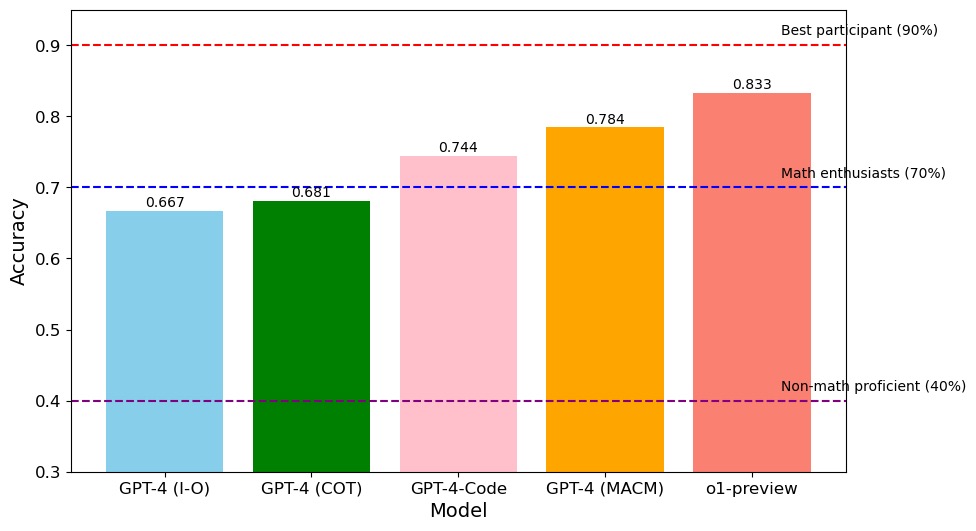
The chart compares the accuracy of five different models (GPT-4 variants and o1-preview) across a task, with accuracy values ranging from 0.3 to 0.9. Three benchmark lines represent performance thresholds: "Best participant (90%)", "Math enthusiasts (70%)", and "Non-math proficient (40%)". The chart uses color-coded bars to distinguish models and dashed horizontal lines to indicate benchmarks.
### Components/Axes
- **X-axis**: Model names (GPT-4 (I-O), GPT-4 (COT), GPT-4-Code, GPT-4 (MACM), o1-preview)
- **Y-axis**: Accuracy (0.3 to 0.9, labeled "Accuracy")
- **Legend**: Located on the right, mapping colors to models:
- Blue: GPT-4 (I-O)
- Green: GPT-4 (COT)
- Pink: GPT-4-Code
- Orange: GPT-4 (MACM)
- Red: o1-preview
- **Dashed Lines**:
- Red (dash-dot): Best participant (90%)
- Blue (dotted): Math enthusiasts (70%)
- Purple (dotted): Non-math proficient (40%)
### Detailed Analysis
- **GPT-4 (I-O)**: Accuracy = 0.667 (blue bar, leftmost)
- **GPT-4 (COT)**: Accuracy = 0.681 (green bar, second from left)
- **GPT-4-Code**: Accuracy = 0.744 (pink bar, third from left)
- **GPT-4 (MACM)**: Accuracy = 0.784 (orange bar, fourth from left)
- **o1-preview**: Accuracy = 0.833 (red bar, rightmost)
All bars are positioned above the "Non-math proficient (40%)" benchmark (purple line) and below the "Best participant (90%)" threshold (red line). The "Math enthusiasts (70%)" benchmark (blue line) is exceeded by all models except GPT-4 (I-O) and GPT-4 (COT).
### Key Observations
1. **o1-preview** achieves the highest accuracy (0.833), surpassing all other models.
2. **GPT-4 (MACM)** (0.784) and **GPT-4-Code** (0.744) show incremental improvements over earlier GPT-4 variants.
3. **GPT-4 (I-O)** and **GPT-4 (COT)** perform similarly (0.667–0.681), both below the "Math enthusiasts" benchmark.
4. No model reaches the "Best participant" threshold (90%), with the closest being o1-preview at 83.3%.
### Interpretation
The data demonstrates a clear trend of increasing accuracy with model complexity or specialization. The o1-preview model outperforms all GPT-4 variants, suggesting it may incorporate advanced reasoning or training techniques. However, all models fall short of the "Best participant" benchmark, indicating room for improvement in solving the task. The "Math enthusiasts" threshold (70%) acts as a mid-tier benchmark, with only three models exceeding it. The "Non-math proficient" baseline (40%) is easily surpassed by all models, highlighting that even basic performance exceeds this group. The absence of a model reaching 90% suggests the task remains challenging for current AI systems, with potential implications for real-world applications requiring near-human accuracy.