\n
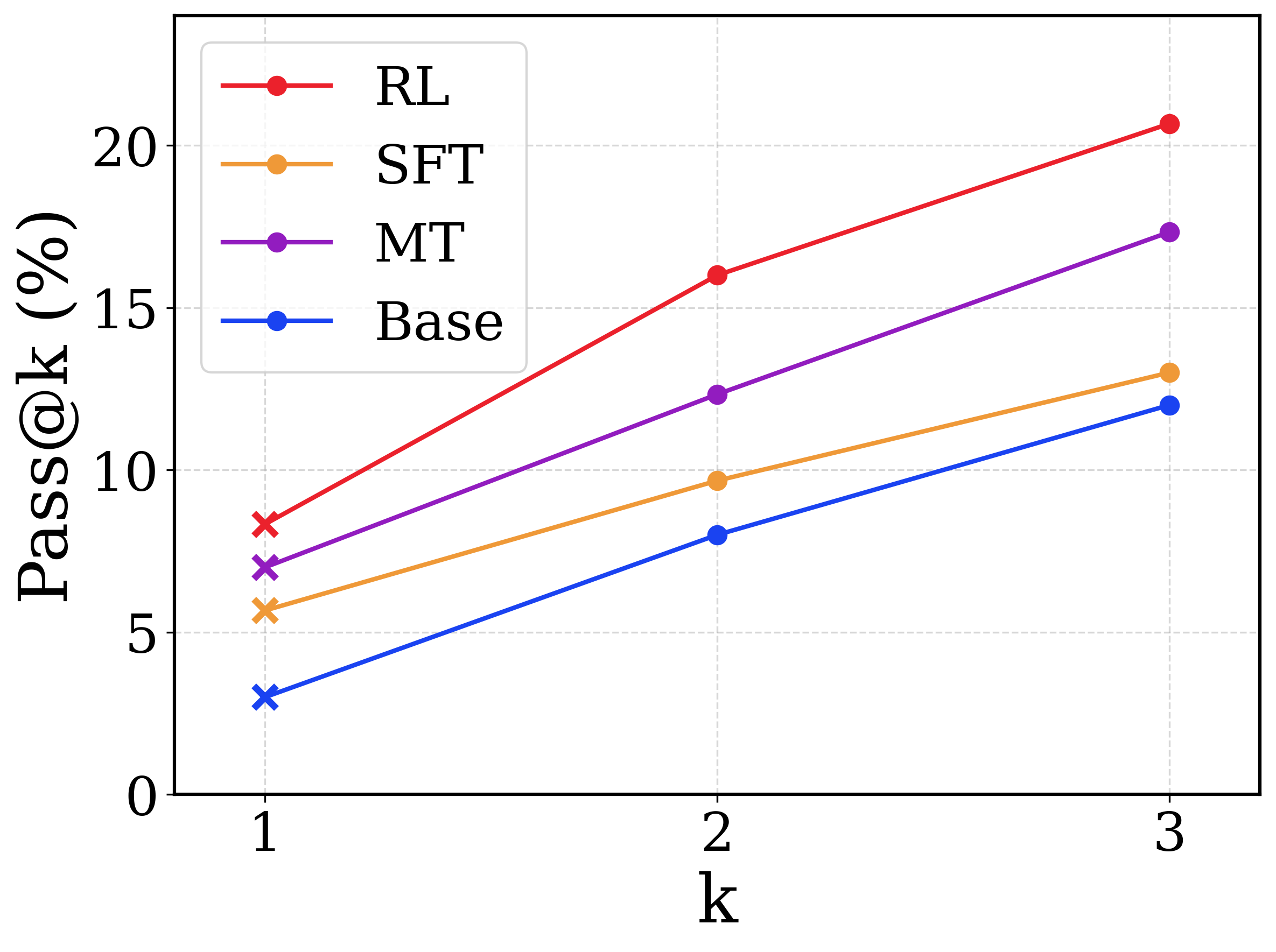
## Line Chart: Pass@k vs. k for Different Models
### Overview
This image presents a line chart comparing the Pass@k metric for four different models (RL, SFT, MT, and Base) across varying values of 'k' (1, 2, and 3). The chart illustrates how the percentage of successful passes changes as 'k' increases for each model.
### Components/Axes
* **X-axis:** Labeled "k", with markers at 1, 2, and 3.
* **Y-axis:** Labeled "Pass@k (%)", with a scale ranging from 0 to 20, incrementing by 5.
* **Legend:** Located in the top-left corner, listing the models and their corresponding colors:
* RL (Red)
* SFT (Orange)
* MT (Purple)
* Base (Blue)
* **Data Series:** Four distinct lines representing each model's performance.
### Detailed Analysis
Let's analyze each line's trend and extract the approximate data points.
* **RL (Red):** The line slopes upward consistently.
* k=1: Approximately 7.5%
* k=2: Approximately 9%
* k=3: Approximately 21%
* **SFT (Orange):** The line also slopes upward, but less steeply than RL.
* k=1: Approximately 4.5%
* k=2: Approximately 8%
* k=3: Approximately 12%
* **MT (Purple):** The line slopes upward, with a moderate steepness.
* k=1: Approximately 7%
* k=2: Approximately 13%
* k=3: Approximately 18%
* **Base (Blue):** The line slopes upward, but is the least steep of all four.
* k=1: Approximately 2.5%
* k=2: Approximately 6%
* k=3: Approximately 12.5%
### Key Observations
* The RL model consistently outperforms the other models across all values of 'k'.
* The Base model consistently underperforms the other models across all values of 'k'.
* All models show an increase in Pass@k as 'k' increases, indicating that allowing more attempts improves performance.
* The difference in performance between the models becomes more pronounced as 'k' increases.
### Interpretation
The chart demonstrates the impact of different training methodologies (RL, SFT, MT, and Base) on the Pass@k metric, which likely represents the success rate of a model in generating acceptable outputs within 'k' attempts. The RL model's superior performance suggests that reinforcement learning is an effective approach for improving the quality of generated outputs. The increasing trend for all models with higher 'k' values indicates a trade-off between efficiency (fewer attempts) and accuracy (higher success rate). The Base model's lower performance suggests that it may require further refinement or a different training strategy. The data suggests that increasing 'k' is a viable strategy for improving performance, but the optimal value of 'k' likely depends on the specific application and the desired balance between efficiency and accuracy. The gap between the models widens as k increases, suggesting that the benefits of the more advanced training methods are more apparent when more attempts are allowed.