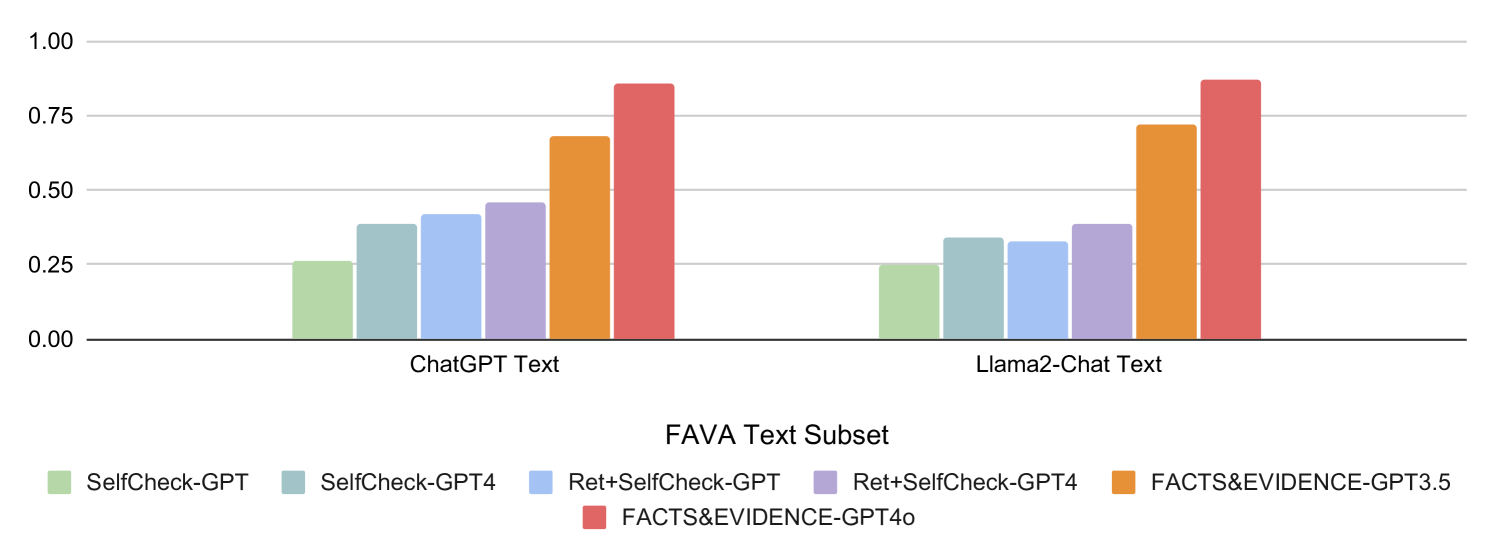
## Bar Chart: Model Performance on FAVA Text Subset
### Overview
The image is a bar chart comparing the performance of different language models and prompting strategies on the FAVA (Factuality, Accuracy, Verifiability, and Auditability) Text Subset. The chart displays the performance of each model/strategy combination for both ChatGPT Text and Llama2-Chat Text. The y-axis represents an unspecified performance metric, ranging from 0.00 to 1.00.
### Components/Axes
* **X-axis:** "FAVA Text Subset" with two categories: "ChatGPT Text" and "Llama2-Chat Text".
* **Y-axis:** Numerical scale ranging from 0.00 to 1.00, with increments of 0.25.
* **Legend:** Located at the bottom of the chart, mapping colors to model/strategy combinations:
* Light Green: "SelfCheck-GPT"
* Light Blue: "SelfCheck-GPT4"
* Blue: "Ret+SelfCheck-GPT"
* Lavender: "Ret+SelfCheck-GPT4"
* Orange: "FACTS&EVIDENCE-GPT3.5"
* Red: "FACTS&EVIDENCE-GPT4o"
### Detailed Analysis
**ChatGPT Text Category:**
* SelfCheck-GPT (Light Green): ~0.26
* SelfCheck-GPT4 (Light Blue): ~0.38
* Ret+SelfCheck-GPT (Blue): ~0.41
* Ret+SelfCheck-GPT4 (Lavender): ~0.46
* FACTS&EVIDENCE-GPT3.5 (Orange): ~0.68
* FACTS&EVIDENCE-GPT4o (Red): ~0.87
**Llama2-Chat Text Category:**
* SelfCheck-GPT (Light Green): ~0.26
* SelfCheck-GPT4 (Light Blue): ~0.33
* Ret+SelfCheck-GPT (Blue): ~0.34
* Ret+SelfCheck-GPT4 (Lavender): ~0.39
* FACTS&EVIDENCE-GPT3.5 (Orange): ~0.72
* FACTS&EVIDENCE-GPT4o (Red): ~0.89
### Key Observations
* For both ChatGPT Text and Llama2-Chat Text, the "FACTS&EVIDENCE-GPT4o" strategy (Red) consistently achieves the highest performance.
* The "SelfCheck-GPT" strategy (Light Green) consistently shows the lowest performance for both text types.
* The performance of each strategy generally increases from "SelfCheck-GPT" to "FACTS&EVIDENCE-GPT4o".
* The performance differences between ChatGPT Text and Llama2-Chat Text are relatively small for each strategy.
### Interpretation
The chart suggests that using the "FACTS&EVIDENCE-GPT4o" prompting strategy leads to the best performance on the FAVA Text Subset for both ChatGPT and Llama2-Chat models. This indicates that this strategy is more effective in ensuring factuality, accuracy, verifiability, and auditability in the generated text. The "SelfCheck-GPT" strategy appears to be the least effective. The consistent trend across both ChatGPT and Llama2-Chat suggests that the effectiveness of these strategies is relatively model-independent.