\n
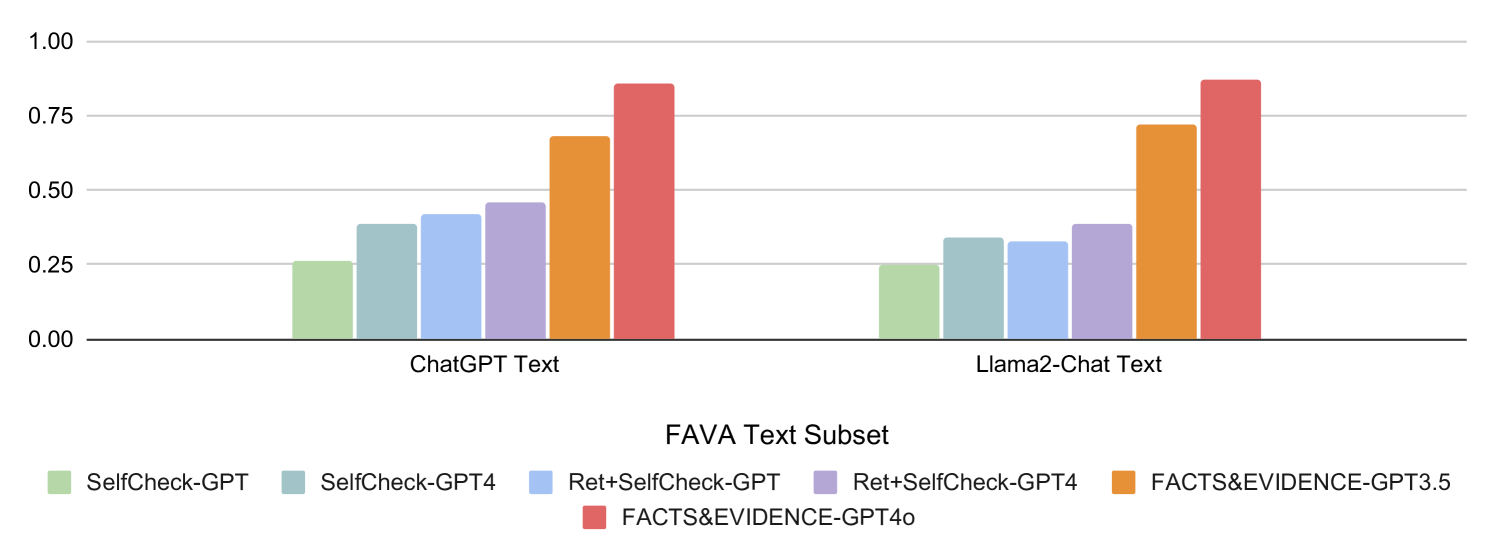
## Bar Chart: FAVA Text Subset Performance Comparison
### Overview
This bar chart compares the performance of several models (SelfCheck-GPT, SelfCheck-GPT4, Ret+SelfCheck-GPT, Ret+SelfCheck-GPT4, FACTS&EVIDENCE-GPT3.5, and FACTS&EVIDENCE-GPT4o) on the FAVA Text Subset, specifically when processing text generated by ChatGPT and Llama2-Chat. The performance metric appears to be a score between 0 and 1, likely representing accuracy or a similar measure.
### Components/Axes
* **X-axis:** "FAVA Text Subset" with two categories: "ChatGPT Text" and "Llama2-Chat Text".
* **Y-axis:** Scale from 0.00 to 1.00, representing the performance score.
* **Legend:** Located at the bottom of the chart, identifying the different models with corresponding colors:
* SelfCheck-GPT (Light Green)
* SelfCheck-GPT4 (Light Blue)
* Ret+SelfCheck-GPT (Orange)
* Ret+SelfCheck-GPT4 (Dark Orange)
* FACTS&EVIDENCE-GPT3.5 (Light Orange)
* FACTS&EVIDENCE-GPT4o (Dark Red)
### Detailed Analysis
The chart consists of six bars for each text source (ChatGPT and Llama2-Chat), representing the performance of each model.
**ChatGPT Text:**
* **SelfCheck-GPT:** Approximately 0.27.
* **SelfCheck-GPT4:** Approximately 0.43.
* **Ret+SelfCheck-GPT:** Approximately 0.63.
* **Ret+SelfCheck-GPT4:** Approximately 0.72.
* **FACTS&EVIDENCE-GPT3.5:** Approximately 0.68.
* **FACTS&EVIDENCE-GPT4o:** Approximately 0.78.
**Llama2-Chat Text:**
* **SelfCheck-GPT:** Approximately 0.26.
* **SelfCheck-GPT4:** Approximately 0.40.
* **Ret+SelfCheck-GPT:** Approximately 0.60.
* **Ret+SelfCheck-GPT4:** Approximately 0.70.
* **FACTS&EVIDENCE-GPT3.5:** Approximately 0.65.
* **FACTS&EVIDENCE-GPT4o:** Approximately 0.76.
**Trends:**
For both ChatGPT and Llama2-Chat text, the performance generally increases as the model complexity increases (from SelfCheck-GPT to FACTS&EVIDENCE-GPT4o). The "Ret+" models consistently outperform the "SelfCheck" models. FACTS&EVIDENCE-GPT4o consistently achieves the highest scores.
### Key Observations
* FACTS&EVIDENCE-GPT4o consistently performs the best across both text sources.
* The performance difference between ChatGPT and Llama2-Chat text is relatively small for each model.
* The largest performance gains are observed when moving from SelfCheck-GPT to Ret+SelfCheck-GPT, suggesting that retrieval augmentation significantly improves performance.
* The difference between FACTS&EVIDENCE-GPT3.5 and FACTS&EVIDENCE-GPT4o is noticeable, indicating an improvement with the newer model.
### Interpretation
The data suggests that the FACTS&EVIDENCE-GPT4o model is the most effective at processing and evaluating text from both ChatGPT and Llama2-Chat, based on the FAVA Text Subset. The consistent improvement with more complex models indicates that incorporating retrieval augmentation ("Ret+") and evidence-based reasoning ("FACTS&EVIDENCE") enhances performance. The relatively small difference in performance between the two text sources suggests that the models are somewhat robust to the specific generation model used. The FAVA Text Subset likely focuses on evaluating factual accuracy or similar qualities, as evidenced by the model names. The chart demonstrates a clear hierarchy of model performance, with FACTS&EVIDENCE-GPT4o at the top and SelfCheck-GPT at the bottom. This information could be used to guide model selection for tasks requiring high accuracy and reliability.