\n
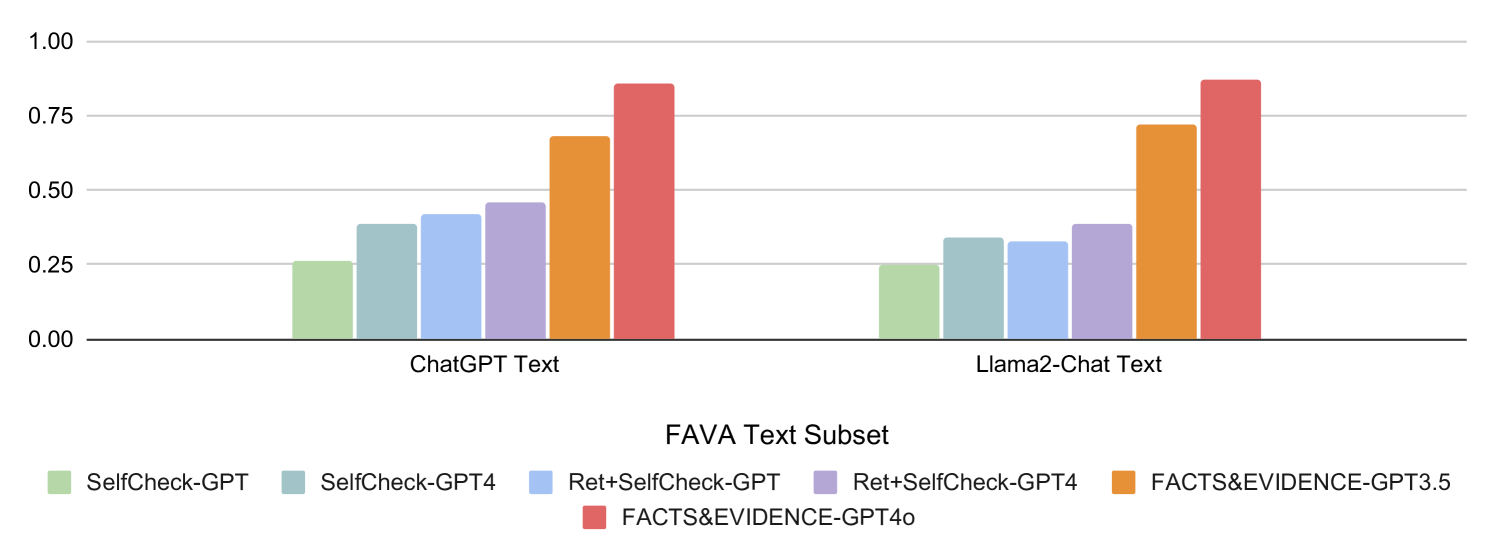
## Grouped Bar Chart: Performance of Fact-Checking Methods on LLM-Generated Text
### Overview
The image displays a grouped bar chart comparing the performance scores of six different fact-checking or self-evaluation methods applied to text generated by two large language models (LLMs). The chart is titled "FAVA Text Subset" at the bottom, indicating the dataset or evaluation framework used. The performance metric is plotted on the y-axis, ranging from 0.00 to 1.00.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **X-Axis (Categories):** Two primary groups representing the source of the text being evaluated:
1. `ChatGPT Text` (Left group)
2. `Llama2-Chat Text` (Right group)
* **Y-Axis (Scale):** A numerical scale from `0.00` to `1.00`, with major gridlines at intervals of 0.25 (0.00, 0.25, 0.50, 0.75, 1.00). The axis label is not explicitly stated but likely represents a score, accuracy, or confidence metric.
* **Legend:** Positioned at the bottom of the chart, centered. It defines six data series (methods), each associated with a unique color:
* Light Green: `SelfCheck-GPT`
* Teal/Grey-Blue: `SelfCheck-GPT4`
* Light Blue: `Ret+SelfCheck-GPT`
* Light Purple: `Ret+SelfCheck-GPT4`
* Orange: `FACTS&EVIDENCE-GPT3.5`
* Red/Salmon: `FACTS&EVIDENCE-GPT4o`
### Detailed Analysis
The chart presents performance scores for each method within the two text source categories. Values are approximate based on visual alignment with the y-axis gridlines.
**1. ChatGPT Text (Left Group):**
* **Trend:** Scores generally increase from left to right within the group, with the `FACTS&EVIDENCE` methods showing a significant jump.
* **Data Points (Approximate):**
* `SelfCheck-GPT` (Light Green): ~0.26
* `SelfCheck-GPT4` (Teal): ~0.38
* `Ret+SelfCheck-GPT` (Light Blue): ~0.42
* `Ret+SelfCheck-GPT4` (Light Purple): ~0.46
* `FACTS&EVIDENCE-GPT3.5` (Orange): ~0.68
* `FACTS&EVIDENCE-GPT4o` (Red): ~0.86
**2. Llama2-Chat Text (Right Group):**
* **Trend:** A similar pattern emerges, with `FACTS&EVIDENCE` methods outperforming the `SelfCheck` variants. The `Ret+SelfCheck-GPT` score appears slightly lower than its counterpart in the ChatGPT group.
* **Data Points (Approximate):**
* `SelfCheck-GPT` (Light Green): ~0.25
* `SelfCheck-GPT4` (Teal): ~0.34
* `Ret+SelfCheck-GPT` (Light Blue): ~0.32
* `Ret+SelfCheck-GPT4` (Light Purple): ~0.39
* `FACTS&EVIDENCE-GPT3.5` (Orange): ~0.72
* `FACTS&EVIDENCE-GPT4o` (Red): ~0.87
### Key Observations
1. **Method Hierarchy:** Across both text sources, the `FACTS&EVIDENCE` methods (using GPT-3.5 and GPT-4o) consistently achieve the highest scores, with `FACTS&EVIDENCE-GPT4o` being the top performer in both cases.
2. **Model Improvement:** For both the `SelfCheck` and `FACTS&EVIDENCE` method families, the variant using a more advanced model (GPT-4 or GPT-4o) scores higher than the one using an earlier model (GPT or GPT-3.5).
3. **Retrieval Effect:** The impact of adding retrieval (`Ret+`) is mixed. For `SelfCheck-GPT4`, retrieval improves the score in both text groups. However, for `SelfCheck-GPT`, retrieval shows a notable improvement on ChatGPT text but a slight decrease on Llama2-Chat text.
4. **Text Source Similarity:** The overall performance pattern and relative ranking of methods are remarkably consistent between text generated by ChatGPT and Llama2-Chat. The absolute scores for the top-performing methods are also very similar.
### Interpretation
This chart likely comes from a research paper evaluating methods for detecting hallucinations or verifying facts in text generated by LLMs. The "FAVA" framework appears to be the benchmark.
The data suggests a clear conclusion: **Methods that explicitly incorporate a fact-checking or evidence-gathering step (`FACTS&EVIDENCE`) dramatically outperform methods that rely solely on the model's own self-assessment (`SelfCheck`)**, regardless of the underlying model used for the check. The significant performance gap (e.g., ~0.46 vs. ~0.86 for ChatGPT text) indicates that retrieval-augmented or evidence-based verification is a far more reliable approach for this task than pure self-evaluation.
Furthermore, the consistent results across two different LLM text sources (ChatGPT and Llama2-Chat) suggest that the effectiveness of these evaluation methods is robust to the specific generator model. The incremental gains from using a more powerful model (GPT-4/o over GPT-3.5/GPT) within each method family are also evident, highlighting the role of model capability in the verification process itself. The anomaly with `Ret+SelfCheck-GPT` on Llama2 text warrants further investigation but does not alter the primary trend.