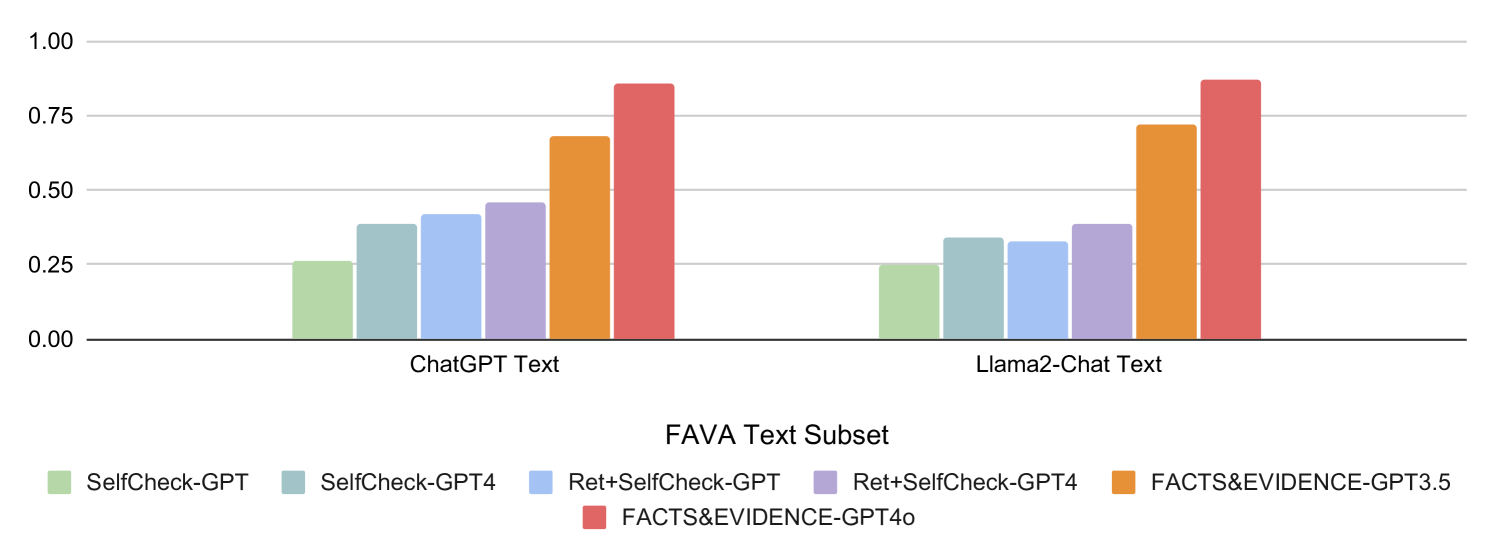
## Bar Chart: Model Performance on FAVA Text Subsets
### Overview
The chart compares the performance of six AI models across two text subsets: "ChatGPT Text" and "Llama2-Chat Text". Performance is measured on a scale from 0.0 to 1.0, with higher values indicating better performance. The models include variations of SelfCheck-GPT, Ret+SelfCheck-GPT, and FACTS&EVIDENCE-GPT versions.
### Components/Axes
- **X-Axis**: Labeled "FAVA Text Subset", divided into two categories:
- "ChatGPT Text" (left)
- "Llama2-Chat Text" (right)
- **Y-Axis**: Labeled "FAVA Text Subset", scaled from 0.0 to 1.0 in increments of 0.25.
- **Legend**: Located at the bottom, mapping colors to models:
- Green: SelfCheck-GPT
- Teal: SelfCheck-GPT4
- Blue: Ret+SelfCheck-GPT
- Purple: Ret+SelfCheck-GPT4
- Orange: FACTS&EVIDENCE-GPT3.5
- Red: FACTS&EVIDENCE-GPT4o
### Detailed Analysis
#### ChatGPT Text Subset
- **SelfCheck-GPT**: ~0.25
- **SelfCheck-GPT4**: ~0.35
- **Ret+SelfCheck-GPT**: ~0.40
- **Ret+SelfCheck-GPT4**: ~0.45
- **FACTS&EVIDENCE-GPT3.5**: ~0.65
- **FACTS&EVIDENCE-GPT4o**: ~0.85
#### Llama2-Chat Text Subset
- **SelfCheck-GPT**: ~0.25
- **SelfCheck-GPT4**: ~0.30
- **Ret+SelfCheck-GPT**: ~0.35
- **Ret+SelfCheck-GPT4**: ~0.35
- **FACTS&EVIDENCE-GPT3.5**: ~0.70
- **FACTS&EVIDENCE-GPT4o**: ~0.85
### Key Observations
1. **FACTS&EVIDENCE-GPT4o** achieves the highest performance (~0.85) in both text subsets, suggesting it is the most effective model.
2. **Ret+SelfCheck-GPT4** consistently outperforms its base version (Ret+SelfCheck-GPT) by ~0.05–0.10 across both subsets.
3. **Llama2-Chat Text** generally shows lower performance than **ChatGPT Text**, except for FACTS&EVIDENCE-GPT4o, which matches the ChatGPT Text result.
4. **SelfCheck-GPT4** improves upon **SelfCheck-GPT** by ~0.10 in both subsets.
### Interpretation
The data demonstrates that models incorporating **FACTS&EVIDENCE** frameworks (GPT3.5 and GPT4o) significantly outperform others, highlighting the importance of evidence-based reasoning in text processing. The incremental improvement from **Ret+SelfCheck-GPT** to **Ret+SelfCheck-GPT4** suggests that model upgrades enhance performance. However, the **Llama2-Chat Text** subset underperforms compared to **ChatGPT Text**, indicating potential differences in training data quality or task alignment. Notably, **FACTS&EVIDENCE-GPT4o** achieves identical performance on both subsets, which may imply robustness to text source variations or a design choice to equalize results. This chart underscores the value of hybrid approaches (e.g., retrieval-augmented generation) and specialized architectures for factual accuracy in AI systems.