## Pie Charts: Errors of GPT-4o, Claude Opus, and LLAMA-3 70B
### Overview
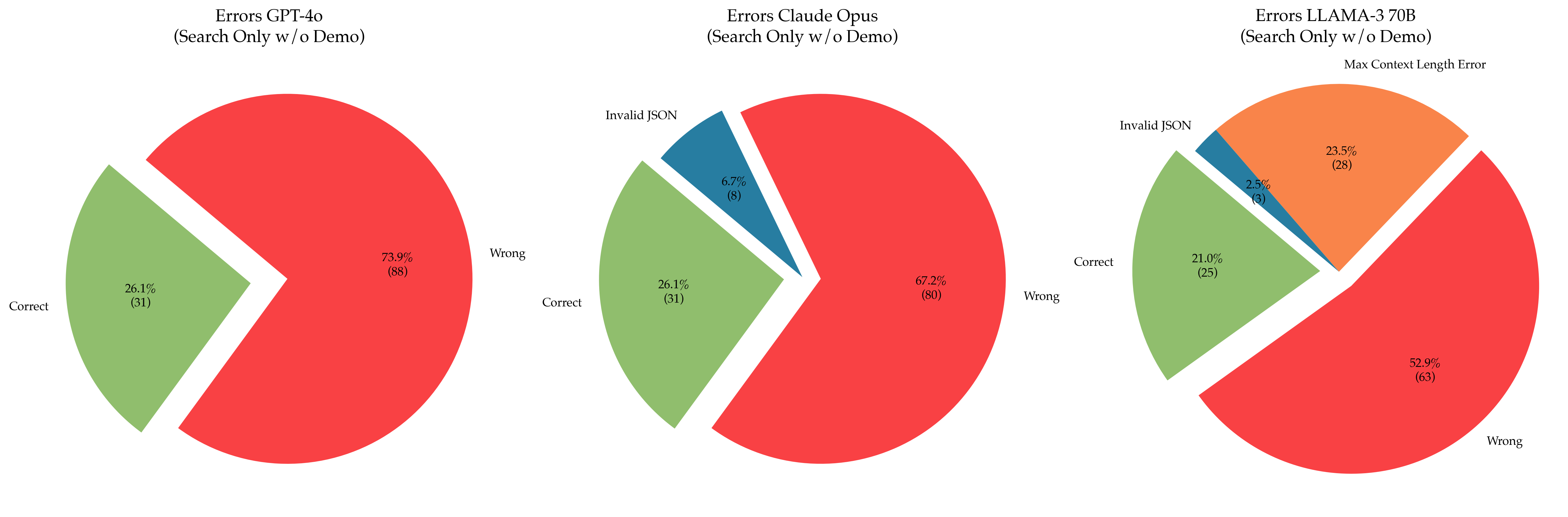
The image presents three pie charts comparing the error rates of three language models: GPT-4o, Claude Opus, and LLAMA-3 70B. The charts show the percentage and count of correct responses, wrong responses, and specific error types (Invalid JSON, Max Context Length Error) when the models are used for search without a demo.
### Components/Axes
Each pie chart represents a language model. The slices of the pie represent the proportion of different response types:
- **Correct:** Correct responses (light green)
- **Wrong:** Incorrect responses (red)
- **Invalid JSON:** Responses that are not valid JSON format (dark blue)
- **Max Context Length Error:** Responses that exceed the maximum context length (orange)
Each slice is labeled with the response type, the percentage of total responses, and the number of responses in parentheses.
### Detailed Analysis
**Chart 1: Errors GPT-4o (Search Only w/o Demo)**
- **Correct:** 26.1% (31)
- **Wrong:** 73.9% (88)
**Chart 2: Errors Claude Opus (Search Only w/o Demo)**
- **Correct:** 26.1% (31)
- **Wrong:** 67.2% (80)
- **Invalid JSON:** 6.7% (8)
**Chart 3: Errors LLAMA-3 70B (Search Only w/o Demo)**
- **Correct:** 21.0% (25)
- **Wrong:** 52.9% (63)
- **Invalid JSON:** 2.5% (3)
- **Max Context Length Error:** 23.5% (28)
### Key Observations
- GPT-4o has the highest percentage of wrong responses (73.9%).
- Claude Opus has a slightly lower percentage of wrong responses (67.2%) compared to GPT-4o, and includes a small percentage of Invalid JSON errors (6.7%).
- LLAMA-3 70B has the lowest percentage of wrong responses (52.9%) but introduces two new error types: Invalid JSON (2.5%) and Max Context Length Error (23.5%).
### Interpretation
The pie charts provide a visual comparison of the error profiles of the three language models under the specified conditions (search only, without demo). GPT-4o struggles the most with providing correct responses, while Claude Opus introduces Invalid JSON errors. LLAMA-3 70B, while having the lowest overall error rate, suffers from Max Context Length Errors, suggesting it may have limitations in handling longer input sequences. The data suggests that the choice of language model depends on the specific application and the tolerance for different types of errors. For example, if JSON format is critical, Claude Opus and LLAMA-3 70B may require additional error handling. If context length is a concern, LLAMA-3 70B may not be the best choice.