\n
## Pie Charts: Error Analysis of Large Language Models
### Overview
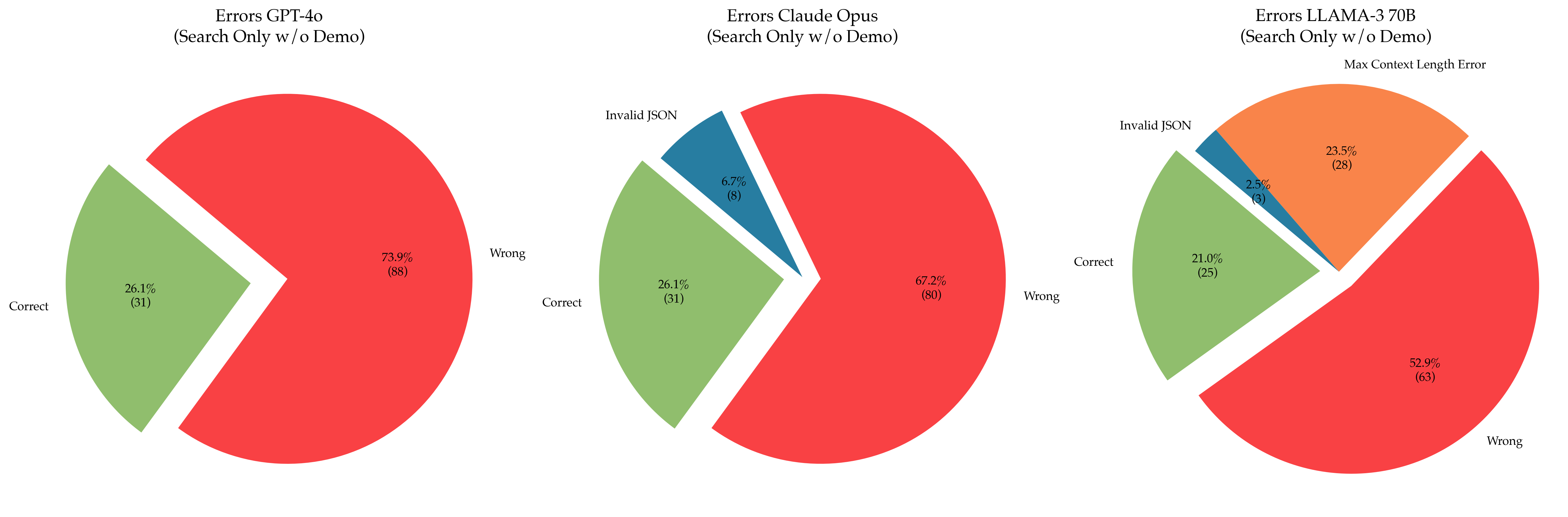
The image presents three pie charts, each representing the error distribution for a different Large Language Model (LLM): GPT-4o, Claude Opus, and LLaMA-3 70B. All models were tested using "Search Only w/o Demo" conditions. The charts categorize errors into three types: "Correct", "Wrong", and "Invalid JSON". The LLaMA-3 70B chart also includes a note about "Max Context Length Error".
### Components/Axes
Each chart has the following components:
* **Title:** Indicates the LLM being analyzed and the testing conditions.
* **Pie Slices:** Represent the proportion of each error type.
* **Labels:** Each slice is labeled with the error type ("Correct", "Wrong", "Invalid JSON") and the count/percentage.
* **Colors:**
* Correct: Light Green
* Wrong: Red
* Invalid JSON: Dark Brown/Orange
### Detailed Analysis or Content Details
**1. GPT-4o (Search Only w/o Demo)**
* **Correct:** 26.1% (31) - Light Green slice.
* **Wrong:** 73.9% (88) - Red slice.
* **Trend:** The vast majority of errors are "Wrong" responses.
**2. Claude Opus (Search Only w/o Demo)**
* **Correct:** 26.1% (31) - Light Green slice.
* **Wrong:** 67.2% (80) - Red slice.
* **Invalid JSON:** 6.7% (6) - Dark Brown/Orange slice.
* **Trend:** Similar to GPT-4o, "Wrong" responses dominate, but Claude Opus also has a small percentage of "Invalid JSON" errors.
**3. LLaMA-3 70B (Search Only w/o Demo)**
* **Correct:** 21.0% (25) - Light Green slice.
* **Wrong:** 52.9% (65) - Red slice.
* **Invalid JSON:** 26.1% (31) - Dark Brown/Orange slice.
* **Note:** "Max Context Length Error" is mentioned in the title.
* **Trend:** LLaMA-3 70B has the lowest percentage of "Correct" responses and a significant proportion of "Invalid JSON" errors.
### Key Observations
* All three models exhibit a high error rate, with "Wrong" responses being the most frequent type.
* Claude Opus has the lowest proportion of "Wrong" responses compared to GPT-4o and LLaMA-3 70B.
* LLaMA-3 70B has the highest proportion of "Invalid JSON" errors, and the lowest proportion of "Correct" responses.
* The "Max Context Length Error" note suggests that LLaMA-3 70B may be particularly susceptible to issues related to input length.
### Interpretation
The data suggests that all three LLMs struggle with accuracy when performing search-only tasks without a demonstration. The high rate of "Wrong" responses indicates that the models often provide incorrect or irrelevant information. The presence of "Invalid JSON" errors, particularly in LLaMA-3 70B, suggests issues with the model's ability to generate valid structured data.
The differences between the models suggest varying strengths and weaknesses. Claude Opus appears to be more reliable in providing correct responses, while LLaMA-3 70B may be more prone to generating invalid JSON and is potentially limited by context length.
The "Search Only w/o Demo" condition is crucial. The lack of a demonstration may hinder the models' ability to understand the desired output format or reasoning process. The results highlight the importance of providing clear instructions and examples to improve the performance of LLMs. The "Max Context Length Error" for LLaMA-3 70B suggests that the model's performance degrades when dealing with longer input sequences, which is a common limitation of transformer-based models.