## Comparative Error Analysis: Three AI Models (Search Only w/o Demo)
### Overview
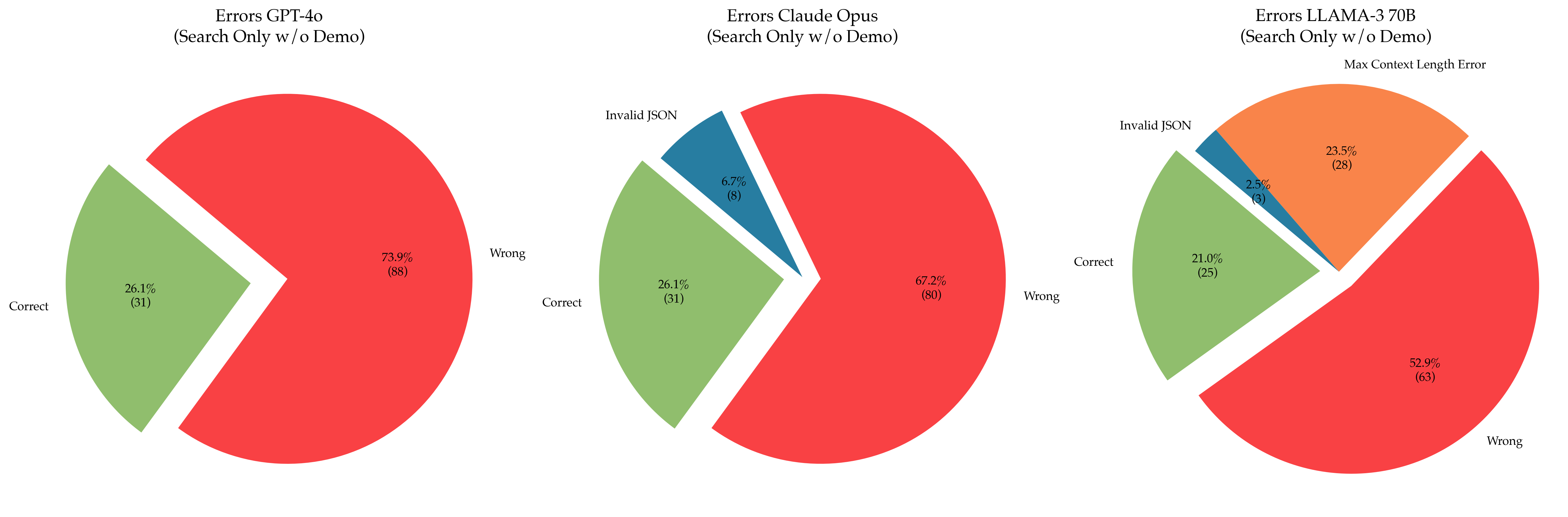
The image displays three horizontally arranged pie charts, each analyzing the error distribution of a different large language model (LLM) under a "Search Only w/o Demo" testing condition. The charts compare the performance of GPT-4o, Claude Opus, and LLAMA-3 70B. Each chart breaks down results into categories of correctness and specific error types.
### Components/Axes
* **Chart Titles (Top-Center of each chart):**
* Left: `Errors GPT-4o (Search Only w/o Demo)`
* Center: `Errors Claude Opus (Search Only w/o Demo)`
* Right: `Errors LLAMA-3 70B (Search Only w/o Demo)`
* **Chart Type:** Pie charts with exploded (pulled-out) segments for emphasis.
* **Legend/Color Key (Inferred from segment labels):**
* **Red:** `Wrong`
* **Green:** `Correct`
* **Blue:** `Invalid JSON`
* **Orange:** `Max Context Length Error`
* **Data Labels:** Each segment contains a percentage and a raw count in parentheses (e.g., `73.9% (88)`).
### Detailed Analysis
**1. GPT-4o (Left Chart)**
* **Segments:**
* **Wrong (Red, dominant segment):** 73.9% (88 instances). This is the largest segment and is not exploded.
* **Correct (Green, exploded segment):** 26.1% (31 instances). This segment is pulled out from the main pie.
* **Total Instances:** 119 (88 + 31).
**2. Claude Opus (Center Chart)**
* **Segments:**
* **Wrong (Red, dominant segment):** 67.2% (80 instances). Largest segment, not exploded.
* **Correct (Green, exploded segment):** 26.1% (31 instances). Pulled out.
* **Invalid JSON (Blue, exploded segment):** 6.7% (8 instances). Pulled out.
* **Total Instances:** 119 (80 + 31 + 8).
**3. LLAMA-3 70B (Right Chart)**
* **Segments:**
* **Wrong (Red, largest segment):** 52.9% (63 instances). Largest segment, not exploded.
* **Max Context Length Error (Orange, exploded segment):** 23.5% (28 instances). Pulled out.
* **Correct (Green, exploded segment):** 21.0% (25 instances). Pulled out.
* **Invalid JSON (Blue, exploded segment):** 2.5% (3 instances). Pulled out.
* **Total Instances:** 119 (63 + 28 + 25 + 3).
### Key Observations
1. **Consistent Sample Size:** All three models were evaluated on the same number of total instances (119), allowing for direct comparison.
2. **Primary Error Type:** The `Wrong` category (red) is the largest error type for all models, though its proportion decreases from GPT-4o (73.9%) to Claude Opus (67.2%) to LLAMA-3 70B (52.9%).
3. **Model-Specific Errors:**
* GPT-4o's errors are binary: only `Correct` or `Wrong`.
* Claude Opus introduces a formatting error (`Invalid JSON`).
* LLAMA-3 70B exhibits a unique, significant error type: `Max Context Length Error` (23.5%), which is the second-largest segment for that model.
4. **Correctness Rate:** The `Correct` rate is similar for GPT-4o and Claude Opus (both 26.1%) but lower for LLAMA-3 70B (21.0%).
5. **Visual Emphasis:** In the Claude Opus and LLAMA-3 70B charts, all non-"Wrong" segments are exploded, visually highlighting the composition of correct answers and specific error subtypes.
### Interpretation
This data suggests a performance and failure mode hierarchy among the tested models for the "Search Only w/o Demo" task.
* **GPT-4o** demonstrates a straightforward failure pattern, with a high rate of substantive errors (`Wrong`) and no observed technical or formatting failures. Its correctness rate is tied for the highest.
* **Claude Opus** shows a slight improvement in the primary `Wrong` error rate compared to GPT-4o and introduces a small percentage of output formatting errors (`Invalid JSON`). Its correctness rate is identical to GPT-4o.
* **LLAMA-3 70B** has the lowest rate of primary `Wrong` errors but also the lowest correctness rate. This is because a substantial portion of its failures (nearly a quarter) are due to a technical limitation—exceeding the maximum context length. This indicates a potential architectural or configuration constraint specific to this model under the test conditions, rather than a pure reasoning failure.
**Conclusion:** While LLAMA-3 70B appears to make fewer "wrong" answers, its overall utility is significantly hampered by context length errors. Claude Opus and GPT-4o have similar correctness, but Claude Opus shows a minor tendency toward formatting issues. The choice of model for this task may depend on whether avoiding context length errors (favoring GPT-4o/Claude Opus) or minimizing outright wrong answers (favoring Claude Opus/LLAMA-3 70B) is the higher priority.