## Pie Charts: Error Distribution in AI Models (Search Only w/o Demo)
### Overview
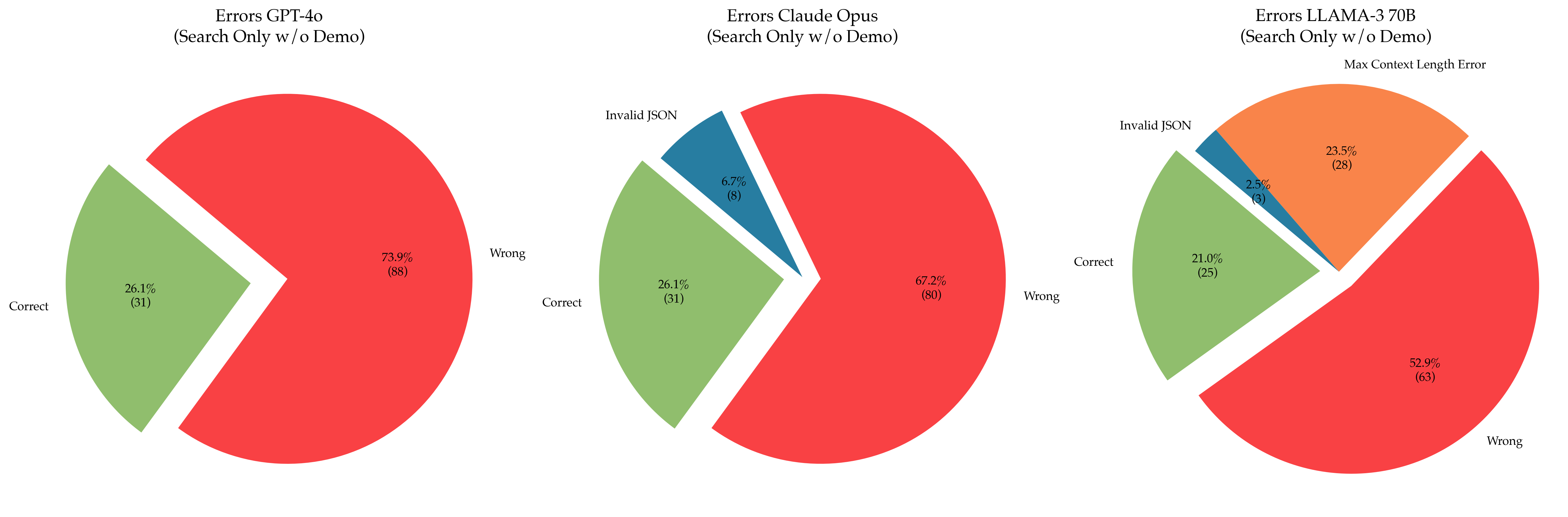
The image contains three pie charts comparing error distributions across three AI models: GPT-4o, Claude Opus, and LLAMA-3 70B. Each chart breaks down results into "Correct," "Wrong," and "Invalid JSON" categories, with numerical counts and percentages provided. The charts are labeled with model names and subtitles specifying "Search Only w/o Demo" (with an additional note for LLAMA-3 about "Max Context Length Error").
---
### Components/Axes
1. **Legend** (Top-left corner):
- **Green**: Correct responses
- **Red**: Wrong responses
- **Blue**: Invalid JSON responses
2. **Chart Structure**:
- Each pie chart represents a single model.
- Segments are labeled with:
- Category names ("Correct," "Wrong," "Invalid JSON")
- Percentages (e.g., 26.1%)
- Numerical counts (e.g., 31)
3. **Subtitles**:
- GPT-4o: "(Search Only w/o Demo)"
- Claude Opus: "(Search Only w/o Demo)"
- LLAMA-3 70B: "(Search Only w/o Demo)" + "(Max Context Length Error)"
---
### Detailed Analysis
#### GPT-4o
- **Correct**: 26.1% (31 responses)
- **Wrong**: 73.9% (88 responses)
- **Invalid JSON**: Not present
#### Claude Opus
- **Correct**: 26.1% (31 responses)
- **Wrong**: 67.2% (80 responses)
- **Invalid JSON**: 6.7% (8 responses)
#### LLAMA-3 70B
- **Correct**: 21.0% (25 responses)
- **Wrong**: 52.9% (63 responses)
- **Invalid JSON**: 23.5% (28 responses)
---
### Key Observations
1. **Error Dominance**:
- GPT-4o has the highest "Wrong" error rate (73.9%), far exceeding the other models.
- LLAMA-3 70B has the highest "Invalid JSON" error rate (23.5%), suggesting input parsing issues.
2. **Consistency in Correct Responses**:
- GPT-4o and Claude Opus share identical "Correct" percentages (26.1%), despite differing total error distributions.
3. **LLAMA-3 Anomaly**:
- The "Max Context Length Error" note implies potential limitations in handling long input sequences, which may contribute to its lower "Correct" rate (21.0%).
---
### Interpretation
- **Model Performance**:
- GPT-4o struggles most with accuracy ("Wrong" errors), while LLAMA-3 faces challenges with input validation ("Invalid JSON").
- Claude Opus balances errors but still has a majority of "Wrong" responses (67.2%).
- **Technical Implications**:
- The "Invalid JSON" errors in Claude Opus and LLAMA-3 suggest issues with structured data handling or input formatting.
- The "Max Context Length Error" for LLAMA-3 hints at architectural constraints affecting performance in search tasks without a demo.
- **Comparative Insights**:
- All models underperform in "Correct" responses, but GPT-4o’s high "Wrong" rate indicates systemic issues in result generation.
- LLAMA-3’s unique error category ("Max Context Length Error") may require targeted optimization for search tasks.
---
### Spatial Grounding & Trend Verification
- **Legend Placement**: Top-left corner, clearly associating colors with categories.
- **Trend Consistency**:
- GPT-4o’s "Wrong" segment (red) dominates visually, aligning with its 73.9% value.
- LLAMA-3’s "Invalid JSON" (blue) is the largest non-red segment, matching its 23.5% count.
---
### Final Notes
The data highlights trade-offs between accuracy and input robustness across models. GPT-4o prioritizes output generation at the cost of correctness, while LLAMA-3’s input validation issues may stem from context length limitations. Claude Opus offers a middle ground but still requires improvement in both accuracy and JSON handling.