TECHNICAL ASSET FINGERPRINT
d51b54b9d585b28f2d94585f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
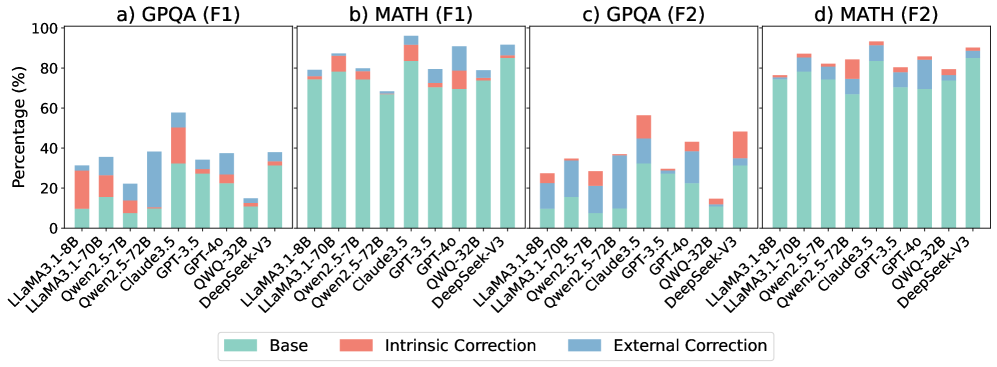
## Stacked Bar Chart: Model Performance on Question Answering and Math Tasks
### Overview
The image presents four stacked bar charts (a, b, c, and d) comparing the performance of several language models on two types of tasks: Question Answering (QA) and Math. Each chart displays the percentage score (F1 score) achieved by each model, broken down into three components: Base, Intrinsic Correction, and External Correction. The models being compared are: LLaMA3.1-8B, LLaMA3.1-70B, Qwen2.5-72B, Qwen2.5-5.72B, Claude3.5, GPT-3.5, QWQ-32B, QWQ-4.0, and DeepSeek-V3.
### Components/Axes
* **X-axis:** Model names (LLaMA3.1-8B, LLaMA3.1-70B, Qwen2.5-72B, Qwen2.5-5.72B, Claude3.5, GPT-3.5, QWQ-32B, QWQ-4.0, DeepSeek-V3).
* **Y-axis:** Percentage (%) - Scale ranges from 0 to 100.
* **Charts:**
* a) GPQA (F1)
* b) MATH (F1)
* c) GPQA (F2)
* d) MATH (F2)
* **Legend:**
* Base (Light Blue)
* Intrinsic Correction (Salmon/Light Red)
* External Correction (Steel Blue)
### Detailed Analysis or Content Details
**Chart a) GPQA (F1)**
* **LLaMA3.1-8B:** Approximately 30% Base, 10% Intrinsic Correction, 10% External Correction, Total ~50%.
* **LLaMA3.1-70B:** Approximately 50% Base, 15% Intrinsic Correction, 15% External Correction, Total ~80%.
* **Qwen2.5-72B:** Approximately 60% Base, 10% Intrinsic Correction, 10% External Correction, Total ~80%.
* **Qwen2.5-5.72B:** Approximately 30% Base, 10% Intrinsic Correction, 10% External Correction, Total ~50%.
* **Claude3.5:** Approximately 30% Base, 20% Intrinsic Correction, 10% External Correction, Total ~60%.
* **GPT-3.5:** Approximately 60% Base, 20% Intrinsic Correction, 10% External Correction, Total ~90%.
* **QWQ-32B:** Approximately 70% Base, 10% Intrinsic Correction, 10% External Correction, Total ~90%.
* **QWQ-4.0:** Approximately 70% Base, 10% Intrinsic Correction, 10% External Correction, Total ~90%.
* **DeepSeek-V3:** Approximately 70% Base, 10% Intrinsic Correction, 10% External Correction, Total ~90%.
**Chart b) MATH (F1)**
* **LLaMA3.1-8B:** Approximately 10% Base, 10% Intrinsic Correction, 5% External Correction, Total ~25%.
* **LLaMA3.1-70B:** Approximately 40% Base, 20% Intrinsic Correction, 10% External Correction, Total ~70%.
* **Qwen2.5-72B:** Approximately 50% Base, 20% Intrinsic Correction, 10% External Correction, Total ~80%.
* **Qwen2.5-5.72B:** Approximately 20% Base, 10% Intrinsic Correction, 5% External Correction, Total ~35%.
* **Claude3.5:** Approximately 20% Base, 20% Intrinsic Correction, 5% External Correction, Total ~45%.
* **GPT-3.5:** Approximately 60% Base, 20% Intrinsic Correction, 5% External Correction, Total ~85%.
* **QWQ-32B:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
* **QWQ-4.0:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
* **DeepSeek-V3:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
**Chart c) GPQA (F2)**
* **LLaMA3.1-8B:** Approximately 20% Base, 15% Intrinsic Correction, 10% External Correction, Total ~45%.
* **LLaMA3.1-70B:** Approximately 60% Base, 15% Intrinsic Correction, 10% External Correction, Total ~85%.
* **Qwen2.5-72B:** Approximately 70% Base, 10% Intrinsic Correction, 5% External Correction, Total ~85%.
* **Qwen2.5-5.72B:** Approximately 20% Base, 15% Intrinsic Correction, 10% External Correction, Total ~45%.
* **Claude3.5:** Approximately 30% Base, 20% Intrinsic Correction, 10% External Correction, Total ~60%.
* **GPT-3.5:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
* **QWQ-32B:** Approximately 80% Base, 5% Intrinsic Correction, 5% External Correction, Total ~90%.
* **QWQ-4.0:** Approximately 80% Base, 5% Intrinsic Correction, 5% External Correction, Total ~90%.
* **DeepSeek-V3:** Approximately 80% Base, 5% Intrinsic Correction, 5% External Correction, Total ~90%.
**Chart d) MATH (F2)**
* **LLaMA3.1-8B:** Approximately 10% Base, 10% Intrinsic Correction, 5% External Correction, Total ~25%.
* **LLaMA3.1-70B:** Approximately 40% Base, 20% Intrinsic Correction, 10% External Correction, Total ~70%.
* **Qwen2.5-72B:** Approximately 50% Base, 20% Intrinsic Correction, 10% External Correction, Total ~80%.
* **Qwen2.5-5.72B:** Approximately 20% Base, 10% Intrinsic Correction, 5% External Correction, Total ~35%.
* **Claude3.5:** Approximately 20% Base, 20% Intrinsic Correction, 5% External Correction, Total ~45%.
* **GPT-3.5:** Approximately 60% Base, 20% Intrinsic Correction, 5% External Correction, Total ~85%.
* **QWQ-32B:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
* **QWQ-4.0:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
* **DeepSeek-V3:** Approximately 70% Base, 15% Intrinsic Correction, 5% External Correction, Total ~90%.
### Key Observations
* Larger models (e.g., LLaMA3.1-70B, Qwen2.5-72B) consistently outperform smaller models (e.g., LLaMA3.1-8B, Qwen2.5-5.72B) across all tasks and metrics.
* GPT-3.5, QWQ-32B, QWQ-4.0, and DeepSeek-V3 generally achieve the highest scores, often exceeding 90% on F2 metrics.
* The "Base" component consistently contributes the largest portion of the overall score for most models.
* Intrinsic and External Correction provide incremental improvements, but their impact varies depending on the model and task.
* The performance gap between F1 and F2 metrics suggests that the models' performance improves with more complex evaluation criteria.
### Interpretation
The data demonstrates a clear correlation between model size and performance on both question answering and math tasks. Larger models, with more parameters, are better equipped to handle the complexities of these tasks. The stacked bar charts reveal that the "Base" performance is the primary driver of overall scores, indicating that the foundational capabilities of the model are crucial. The "Intrinsic Correction" and "External Correction" components suggest that techniques for refining the model's output (either through internal adjustments or external feedback) can further enhance performance, but their impact is less substantial than the base model's capabilities. The consistent high performance of GPT-3.5, QWQ-32B, QWQ-4.0, and DeepSeek-V3 suggests that these models represent state-of-the-art performance in this domain. The difference between F1 and F2 scores indicates that the models are more robust when evaluated with more nuanced and challenging criteria. This suggests that while models may perform well on simpler tasks, their ability to generalize to more complex scenarios is still limited.
DECODING INTELLIGENCE...