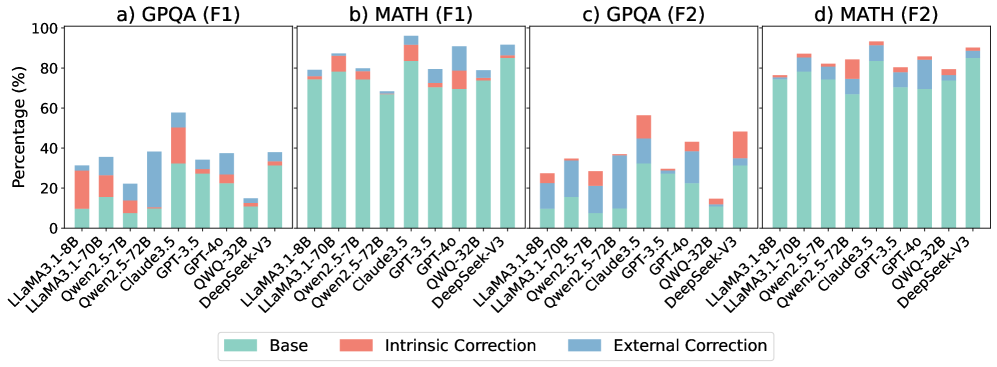
## Bar Charts: Model Performance by Correction Type and Task
### Overview
The image contains four grouped bar charts comparing model performance across four categories:
a) GPQA (F1), b) MATH (F1), c) GPQA (F2), d) MATH (F2).
Each chart evaluates three correction approaches: **Base** (green), **Intrinsic Correction** (red), and **External Correction** (blue).
Models compared include LLaMA, Qwen, Claude, GPT, and DeepSeek with version suffixes (e.g., 3.1-8B, 32B, V3).
---
### Components/Axes
- **X-axis**: Model names and versions (e.g., "LLaMA3.1-8B", "DeepSeek-V3").
- **Y-axis**: Performance percentage (0–100%).
- **Legend**: Located at the bottom, mapping colors to correction types:
- Green = Base
- Red = Intrinsic Correction
- Blue = External Correction
---
### Detailed Analysis
#### a) GPQA (F1)
- **Trend**: Intrinsic Correction (red) dominates performance across most models.
- **Key Data Points**:
- LLaMA3.1-8B: Base ~10%, Intrinsic ~25%, External ~5%.
- Qwen2.5-72B: Base ~30%, Intrinsic ~35%, External ~20%.
- DeepSeek-V3: Base ~40%, Intrinsic ~45%, External ~15%.
#### b) MATH (F1)
- **Trend**: External Correction (blue) outperforms others for most models.
- **Key Data Points**:
- GPT-40: Base ~60%, Intrinsic ~10%, External ~30%.
- Claude3.5: Base ~70%, Intrinsic ~5%, External ~15%.
- DeepSeek-V3: Base ~80%, Intrinsic ~5%, External ~10%.
#### c) GPQA (F2)
- **Trend**: Base performance declines sharply for some models.
- **Key Data Points**:
- LLaMA3.1-8B: Base ~5%, Intrinsic ~20%, External ~10%.
- Qwen2.5-72B: Base ~15%, Intrinsic ~25%, External ~10%.
- DeepSeek-V3: Base ~10%, Intrinsic ~30%, External ~5%.
#### d) MATH (F2)
- **Trend**: Intrinsic Correction (red) shows mixed results; External Correction (blue) remains strong.
- **Key Data Points**:
- GPT-40: Base ~75%, Intrinsic ~10%, External ~15%.
- Claude3.5: Base ~80%, Intrinsic ~5%, External ~10%.
- DeepSeek-V3: Base ~85%, Intrinsic ~5%, External ~5%.
---
### Key Observations
1. **Intrinsic Correction** excels in GPQA (F1) but underperforms in MATH (F1).
2. **External Correction** dominates MATH (F1) but has minimal impact in GPQA (F1).
3. **F2 Metrics** show significant drops in Base performance for GPQA, while MATH (F2) retains higher Base scores.
4. **DeepSeek-V3** consistently achieves the highest Base performance across tasks.
---
### Interpretation
- **Task-Specific Correction Efficacy**: Intrinsic Correction aligns better with GPQA (F1), suggesting task-specific optimization, while External Correction benefits MATH (F1), possibly due to broader knowledge integration.
- **F2 Metric Sensitivity**: The decline in Base performance for GPQA (F2) implies stricter evaluation criteria, whereas MATH (F2) retains robustness.
- **Model Robustness**: DeepSeek-V3’s high Base scores indicate inherent model strength, reducing reliance on corrections.
- **Outliers**: Qwen2.5-72B in GPQA (F2) shows a notable 25% Intrinsic Correction gain, suggesting potential for targeted improvements.
The data highlights the importance of aligning correction strategies with both task requirements and evaluation metrics. Future work could explore hybrid approaches to leverage the strengths of both correction types.