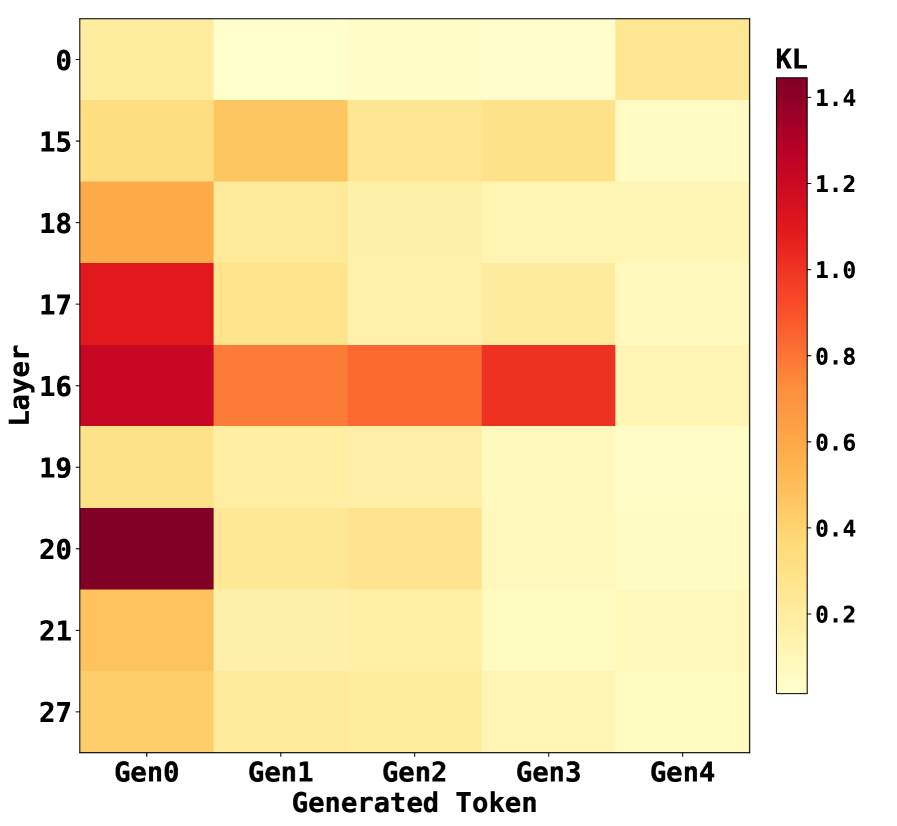
## Heatmap: Kullback-Leibler (KL) Divergence
### Overview
This image presents a heatmap visualizing the Kullback-Leibler (KL) divergence between generated tokens across different layers. The heatmap displays KL divergence values as color intensities, with darker reds indicating higher divergence and lighter yellows indicating lower divergence. The x-axis represents generated tokens (Gen0 to Gen4), and the y-axis represents layers (0, 15, 16, 17, 18, 19, 20, 21, 27).
### Components/Axes
* **X-axis:** "Generated Token" with categories: Gen0, Gen1, Gen2, Gen3, Gen4.
* **Y-axis:** "Layer" with categories: 0, 15, 16, 17, 18, 19, 20, 21, 27.
* **Color Scale/Legend:** Located on the right side of the heatmap, representing KL divergence values ranging from 0.0 (light yellow) to 1.4 (dark red). The scale is marked with values: 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4.
### Detailed Analysis
The heatmap shows varying KL divergence values across different layers and generated tokens.
* **Gen0:** KL divergence is relatively low across all layers, ranging from approximately 0.2 to 0.6. The values appear fairly consistent.
* **Gen1:** KL divergence is generally low, similar to Gen0, ranging from approximately 0.2 to 0.6.
* **Gen2:** KL divergence remains low, ranging from approximately 0.2 to 0.6.
* **Gen3:** Exhibits significantly higher KL divergence values, particularly for layers 16, 17, and 18. The values range from approximately 0.6 to 1.4.
* **Gen4:** KL divergence is generally low, similar to Gen0, Gen1, and Gen2, ranging from approximately 0.2 to 0.6.
Specifically:
* Layer 0: KL divergence is approximately 0.2 for all generated tokens.
* Layer 15: KL divergence is approximately 0.4 for Gen0, Gen1, Gen2, and Gen4, and approximately 0.8 for Gen3.
* Layer 16: KL divergence is approximately 0.6 for Gen0, Gen1, Gen2, and Gen4, and approximately 1.2 for Gen3.
* Layer 17: KL divergence is approximately 0.6 for Gen0, Gen1, Gen2, and Gen4, and approximately 1.3 for Gen3.
* Layer 18: KL divergence is approximately 0.6 for Gen0, Gen1, Gen2, and Gen4, and approximately 1.1 for Gen3.
* Layer 19: KL divergence is approximately 0.4 for all generated tokens.
* Layer 20: KL divergence is approximately 0.4 for all generated tokens.
* Layer 21: KL divergence is approximately 0.4 for all generated tokens.
* Layer 27: KL divergence is approximately 0.2 for all generated tokens.
### Key Observations
* Gen3 consistently exhibits the highest KL divergence values across layers 15-18, indicating a significant difference between the generated token distribution and the expected distribution at those layers.
* Gen0, Gen1, Gen2, and Gen4 show relatively consistent and low KL divergence values across all layers.
* Layers 16, 17, and 18 appear to be particularly sensitive to changes in the generated token, as evidenced by the higher divergence values for Gen3.
### Interpretation
The heatmap suggests that the generated token Gen3 introduces a substantial shift in the distribution of activations within layers 16-18 of the model. This could indicate that Gen3 represents a significantly different or more complex pattern than the other generated tokens. The low KL divergence for Gen0, Gen1, Gen2, and Gen4 suggests that these tokens are more consistent with the model's learned representations.
The higher KL divergence in layers 16-18 for Gen3 might signify that these layers are crucial for processing the specific features or patterns present in Gen3, and the model struggles to represent Gen3 effectively within these layers. This could be due to Gen3 being an outlier, a novel input, or a result of a specific generation process. Further investigation would be needed to determine the underlying cause of this divergence and its implications for the model's performance. The consistent low divergence for the other tokens suggests they are well-represented by the model's existing knowledge.