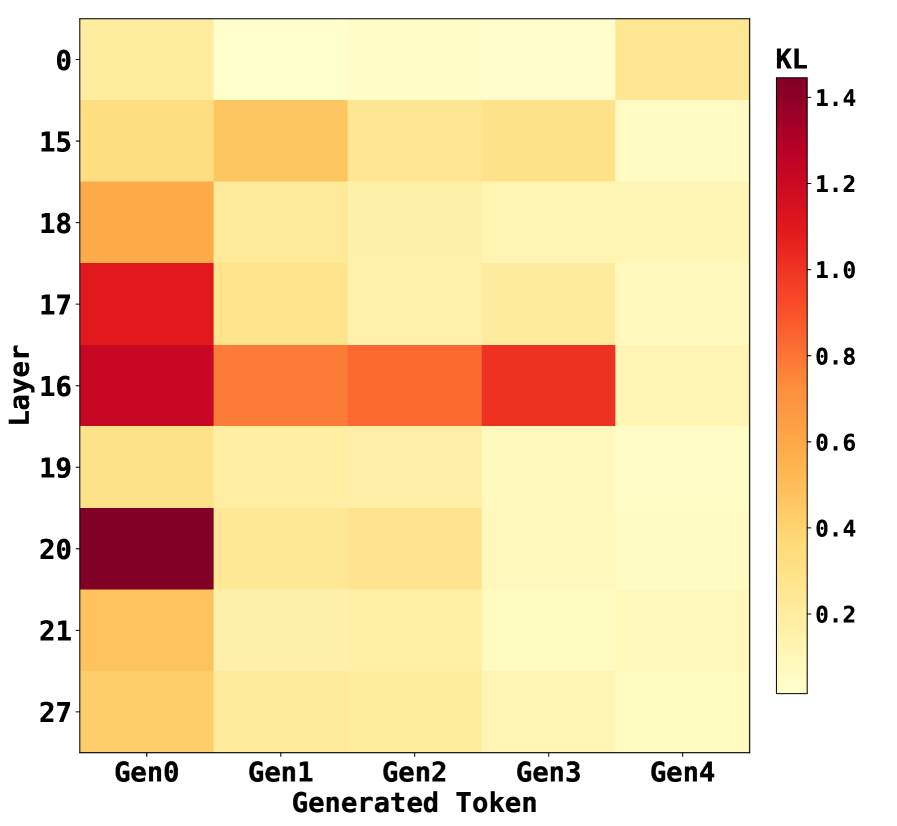
## Heatmap: KL Divergence Across Layers and Generated Tokens
### Overview
The image is a heatmap visualizing KL divergence values across different layers (y-axis) and generated token generations (x-axis). The color gradient ranges from light yellow (low KL) to dark red (high KL), with a legend indicating values from 0.2 to 1.4.
### Components/Axes
- **X-axis (Generated Token)**: Categorized as Gen0, Gen1, Gen2, Gen3, Gen4.
- **Y-axis (Layer)**: Discrete layers labeled 0, 15, 16, 17, 18, 19, 20, 21, 27.
- **Legend**: Positioned on the right, labeled "KL" with a gradient from light yellow (0.2) to dark red (1.4).
### Detailed Analysis
- **Layer 0**: Uniformly light yellow across all generations (KL ≈ 0.2–0.4).
- **Layer 15**: Light yellow to pale orange (KL ≈ 0.4–0.6).
- **Layer 16**:
- Gen0: Dark red (KL ≈ 1.4).
- Gen1–Gen2: Orange-red (KL ≈ 1.0–1.2).
- Gen3–Gen4: Light yellow (KL ≈ 0.2–0.4).
- **Layer 17**:
- Gen0: Dark red (KL ≈ 1.4).
- Gen1–Gen4: Pale orange (KL ≈ 0.4–0.6).
- **Layer 18**: Pale orange to light yellow (KL ≈ 0.4–0.6).
- **Layer 19**: Light yellow (KL ≈ 0.2–0.4).
- **Layer 20**:
- Gen0: Darkest red (KL ≈ 1.4).
- Gen1–Gen4: Light yellow (KL ≈ 0.2–0.4).
- **Layer 21**: Pale orange (KL ≈ 0.4–0.6).
- **Layer 27**: Uniformly light yellow (KL ≈ 0.2–0.4).
### Key Observations
1. **High KL in Early Layers/Generations**:
- Layers 16, 17, and 20 exhibit the highest KL values, particularly in Gen0 and Gen1.
- Layer 20, Gen0 has the maximum KL (≈1.4).
2. **Decline in Later Generations**:
- For layers 16 and 17, KL drops sharply after Gen2.
- Layer 20’s KL plummets after Gen0.
3. **Consistency in Higher Layers**:
- Layers 19, 21, and 27 show minimal KL divergence across all generations.
4. **Color-Legend Consistency**:
- Dark red cells (highest KL) align with the legend’s upper range (1.2–1.4).
- Light yellow cells (lowest KL) match the legend’s lower range (0.2–0.4).
### Interpretation
The heatmap suggests that **early layers (0–20)** and **early generated tokens (Gen0–Gen2)** exhibit significantly higher KL divergence, indicating greater divergence in model outputs or representations at these stages. This could reflect:
- **Critical Processing in Early Layers**: Lower layers (e.g., 16, 17, 20) may handle foundational features or attention mechanisms with higher variability.
- **Stabilization in Later Generations**: The sharp KL drop in later generations (Gen3–Gen4) implies convergence toward stable representations.
- **Anomaly in Layer 20, Gen0**: The extreme KL value here might indicate a unique or outlier feature in this layer’s processing.
The data highlights a trade-off between early-stage variability and later-stage stability, with higher layers (e.g., 27) showing minimal divergence, possibly due to hierarchical feature abstraction in the model.