TECHNICAL ASSET FINGERPRINT
d593ff814ef24fc12576c9af
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
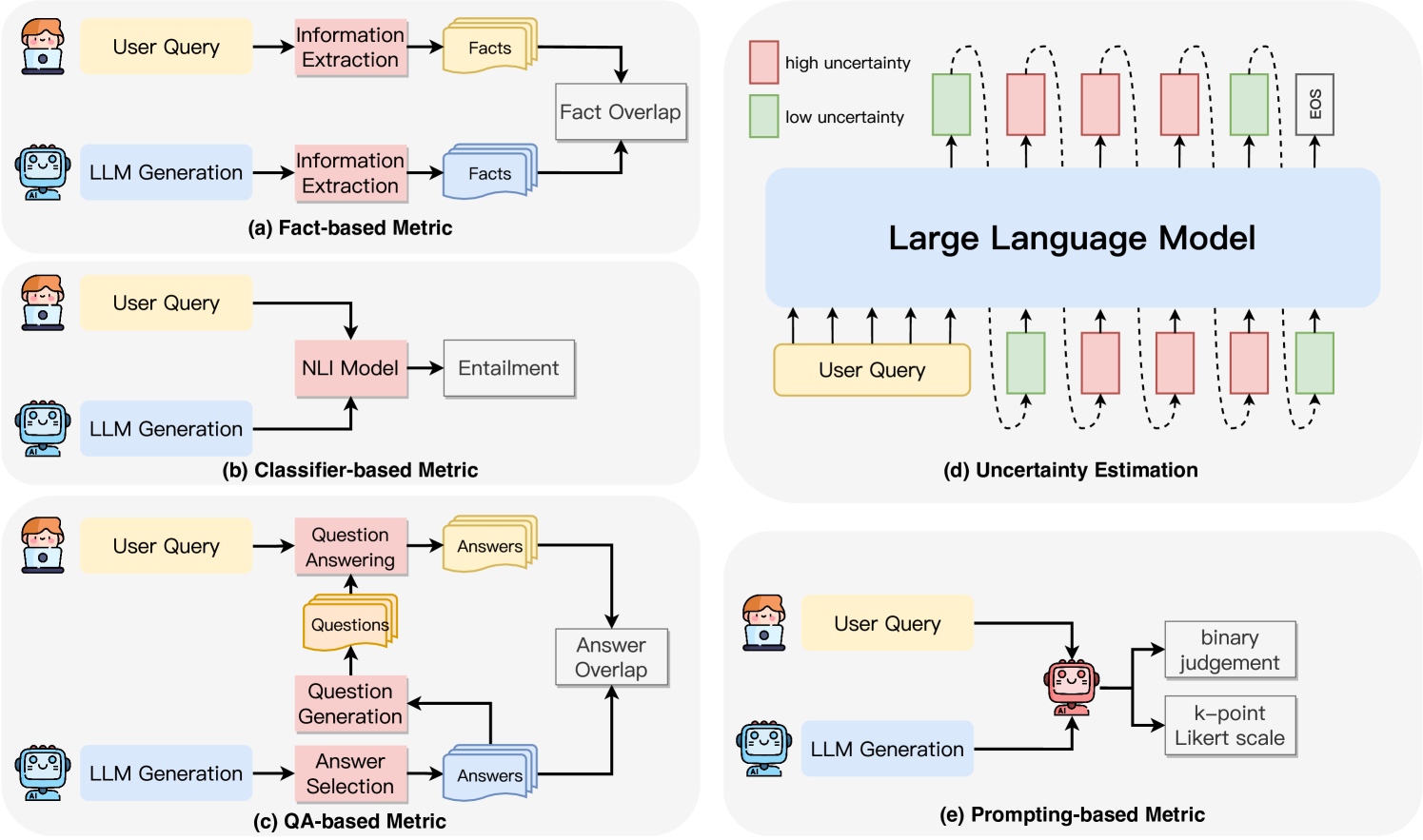
## Diagram Set: LLM Evaluation Metrics and Uncertainty Estimation
### Overview
The image is a composite of five distinct diagrams, labeled (a) through (e), illustrating different methodological frameworks for evaluating the outputs of Large Language Models (LLMs) and for estimating their uncertainty. The diagrams use a consistent visual language with icons representing a human user (with a laptop) and an AI model (robot), along with color-coded boxes and arrows to denote data flow and processing steps.
### Components/Axes
The image is divided into five panels:
* **Top Left (a):** "Fact-based Metric"
* **Middle Left (b):** "Classifier-based Metric"
* **Bottom Left (c):** "QA-based Metric"
* **Top Right (d):** "Uncertainty Estimation"
* **Bottom Right (e):** "Prompting-based Metric"
**Common Visual Elements:**
* **Icons:** A human user icon (person with laptop) and an AI model icon (robot head).
* **Color Coding:**
* Yellow boxes: "User Query"
* Light Blue boxes: "LLM Generation"
* Pink boxes: Processing/Model steps (e.g., "Information Extraction", "NLI Model", "Question Answering").
* Gray boxes: Final outputs or comparison metrics (e.g., "Fact Overlap", "Entailment", "Answer Overlap").
* In diagram (d): Red boxes = "high uncertainty", Green boxes = "low uncertainty".
* **Arrows:** Indicate the direction of data flow between components.
### Detailed Analysis
#### **(a) Fact-based Metric**
* **Flow:** Two parallel pipelines.
1. **Top Pipeline:** `User Query` -> `Information Extraction` -> `Facts` (represented as a stack of documents).
2. **Bottom Pipeline:** `LLM Generation` -> `Information Extraction` -> `Facts` (another stack).
* **Comparison:** The two sets of extracted `Facts` are fed into a `Fact Overlap` module, which presumably computes a similarity or accuracy score based on shared factual elements.
#### **(b) Classifier-based Metric**
* **Flow:** A single, converging pipeline.
* **Process:** Both the `User Query` and the `LLM Generation` are input simultaneously into an `NLI Model` (Natural Language Inference Model).
* **Output:** The NLI Model produces an `Entailment` judgment, classifying the relationship between the query and the generation (e.g., entailment, contradiction, neutral).
#### **(c) QA-based Metric**
* **Flow:** A complex, multi-stage pipeline with a feedback loop.
* **Process:**
1. The `User Query` is sent to a `Question Answering` module to produce a set of `Answers`.
2. The `LLM Generation` is sent to an `Answer Selection` module.
3. A `Question Generation` module creates `Questions` from the LLM's generation. These questions are fed back into the `Question Answering` module.
4. The `Answers` generated from the original user query and the answers selected/derived from the LLM generation are compared via an `Answer Overlap` metric.
#### **(d) Uncertainty Estimation**
* **Structure:** This diagram is distinct, showing the internal state of an LLM.
* **Components:**
* A large central block labeled `Large Language Model`.
* **Input:** A `User Query` (yellow box) is fed into the model from the bottom.
* **Output Sequence:** The model generates a sequence of tokens. Each token is associated with an uncertainty level, visualized as a colored box above it.
* **Legend (Top Left):** Red box = `high uncertainty`, Green box = `low uncertainty`.
* **Sequence Pattern:** The generated sequence shows an alternating pattern of high (red) and low (green) uncertainty tokens, culminating in an `EOS` (End of Sequence) token, which is marked with low uncertainty (green).
* **Visual Metaphor:** Dotted, curved arrows above the uncertainty boxes suggest the model's internal sampling or probability distribution over the vocabulary at each step.
#### **(e) Prompting-based Metric**
* **Flow:** A direct evaluation pipeline.
* **Process:** Both the `User Query` and the `LLM Generation` are fed into a central evaluation module, represented by a robot icon (suggesting another LLM or a specialized judge model).
* **Outputs:** This evaluator produces one of two types of output:
1. `binary judgement` (e.g., good/bad, correct/incorrect).
2. `k-point Likert scale` (e.g., a rating from 1 to 5).
### Key Observations
1. **Methodological Spectrum:** The diagrams present a spectrum of evaluation complexity, from direct comparison of extracted facts (a) and classifier-based judgment (b), to more elaborate QA-based retrieval (c) and prompting-based LLM-as-judge approaches (e).
2. **Uncertainty Visualization:** Diagram (d) uniquely visualizes the token-by-token uncertainty of an LLM's generation process, highlighting that confidence can vary significantly within a single response.
3. **Common Inputs:** All evaluation metrics (a, b, c, e) fundamentally rely on comparing the `LLM Generation` against the original `User Query` or information derived from it.
4. **Abstraction Level:** The diagrams are high-level flowcharts. They abstract away specific model architectures, datasets, or scoring algorithms, focusing instead on the conceptual pipeline of each evaluation strategy.
### Interpretation
This set of diagrams serves as a taxonomy of approaches for assessing LLM performance and reliability. It moves beyond simple accuracy metrics to illustrate more nuanced evaluation paradigms.
* **Fact-based (a) and QA-based (c) Metrics** emphasize **grounding and retrieval**. They treat evaluation as a problem of verifying whether the LLM's output contains or aligns with specific, extractable pieces of information from a source (the query or an implicit knowledge base). The QA-based method is particularly sophisticated, using question generation to probe the LLM's output for answerable content.
* **Classifier-based Metric (b)** frames evaluation as a **natural language inference task**, leveraging pre-trained models to judge logical relationships (entailment) between query and response.
* **Prompting-based Metric (e)** represents the emerging paradigm of using **LLMs themselves as evaluators**, leveraging their language understanding to provide nuanced, scalable judgments that mimic human rating scales.
* **Uncertainty Estimation (d)** addresses a critical, often hidden, dimension of LLM behavior: **model confidence**. The alternating high/low uncertainty pattern suggests that even within a coherent response, the model may be highly confident about some tokens (common words, factual anchors) while being much less sure about others (specific details, novel phrasing). This has profound implications for trustworthiness; a response might be fluent overall but contain uncertain, potentially hallucinated, elements.
**Collectively, these diagrams argue that robust LLM evaluation is multi-faceted.** It requires checking factual consistency, logical soundness, answerability, and the model's own confidence. The choice of metric depends on the application's needs: a medical QA system might prioritize fact-based and uncertainty-aware metrics, while a creative writing assistant might be better served by a prompting-based Likert scale evaluation. The image provides a conceptual map for navigating these choices.
DECODING INTELLIGENCE...