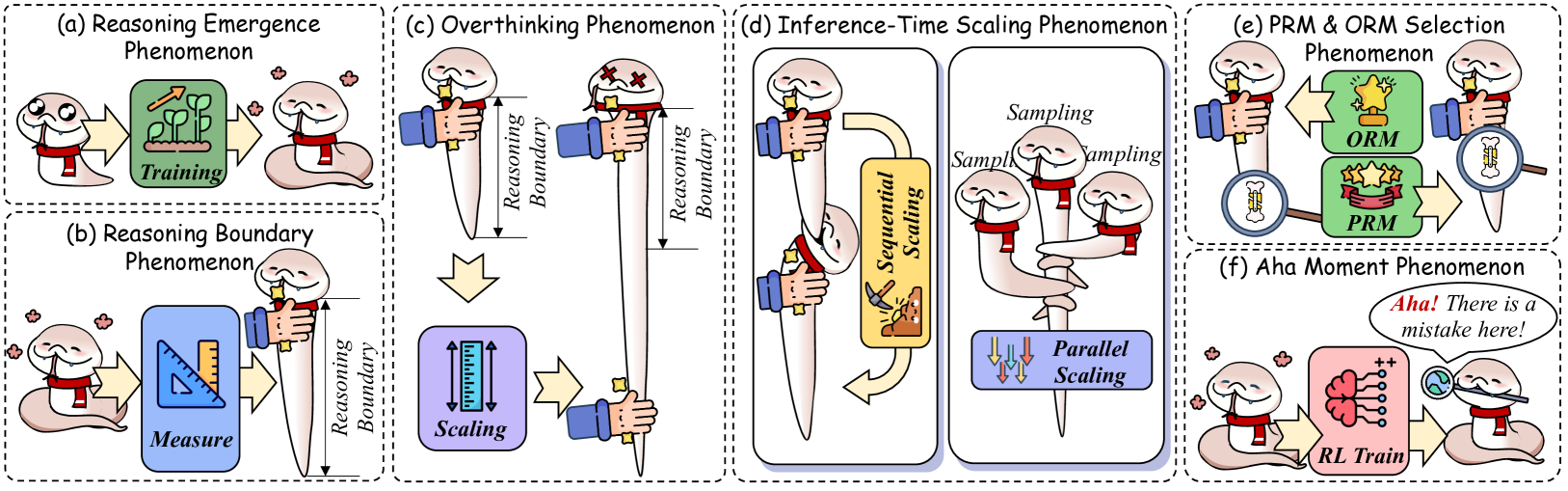
## Diagram: AI Training and Reasoning Phenomena
### Overview
The image is a segmented diagram illustrating six distinct phenomena related to AI training, reasoning, and optimization. Each section uses cartoon-style visuals (e.g., snakes with red scarves) to represent abstract concepts, connected by arrows and labeled components. The diagram emphasizes scaling, boundary conditions, and emergent behaviors in AI systems.
---
### Components/Axes
1. **Sections (a)-(f)**: Six labeled boxes, each depicting a phenomenon:
- **(a) Reasoning Emergence Phenomenon**: Training → Reasoning
- **(b) Reasoning Boundary Phenomenon**: Measure → Scaling
- **(c) Overthinking Phenomenon**: Scaling → Boundary
- **(d) Inference-Time Scaling Phenomenon**: Sequential vs. Parallel Scaling
- **(e) PRM & ORM Selection Phenomenon**: ORM vs. PRM
- **(f) Aha Moment Phenomenon**: RL Train → Error Detection
2. **Visual Elements**:
- **Snakes**: Represent AI agents or models (red scarves denote training).
- **Arrows**: Indicate causal relationships or processes.
- **Labels**: Text boxes with terms like "Training," "Scaling," "ORM," "PRM," and "Aha!"
- **Icons**: Trophies (ORM), magnifying glasses (PRM), and brain diagrams (RL training).
---
### Detailed Analysis
#### (a) Reasoning Emergence Phenomenon
- **Input**: Snake with a thought bubble labeled "Training."
- **Output**: Snake with a green box labeled "Training" and an arrow pointing to a reasoning-capable snake.
- **Key Text**: "Training" (green box), "Reasoning Emergence."
#### (b) Reasoning Boundary Phenomenon
- **Input**: Snake holding a measuring tape labeled "Measure."
- **Output**: Snake with a ruler labeled "Scaling" and a boundary marker.
- **Key Text**: "Measure," "Scaling," "Reasoning Boundary."
#### (c) Overthinking Phenomenon
- **Input**: Snake with crossed eyes (overthinking) and a hand holding a ruler.
- **Output**: Arrows pointing to "Scaling" and "Boundary" with a collapsed snake (X marks).
- **Key Text**: "Overthinking," "Scaling," "Boundary."
#### (d) Inference-Time Scaling Phenomenon
- **Input**: Snake with a magnifying glass labeled "Sampling."
- **Output**: Two paths:
- **Sequential Scaling**: Snake with a ruler.
- **Parallel Scaling**: Snake with multiple arrows.
- **Key Text**: "Sequential Scaling," "Parallel Scaling," "Sampling."
#### (e) PRM & ORM Selection Phenomenon
- **Input**: Snake with a trophy labeled "ORM" and a magnifying glass labeled "PRM."
- **Output**: Arrows pointing to ORM (trophy) and PRM (magnifying glass).
- **Key Text**: "ORM," "PRM."
#### (f) Aha Moment Phenomenon
- **Input**: Snake with a brain diagram labeled "RL Train."
- **Output**: Speech bubble: "Aha! There is a mistake here!" and a globe icon.
- **Key Text**: "Aha! There is a mistake here!", "RL Train."
---
### Key Observations
1. **Causal Flow**: Training leads to reasoning, but overthinking and scaling boundaries limit performance.
2. **Scaling Trade-offs**: Sequential vs. parallel scaling impacts inference efficiency.
3. **Method Selection**: ORM (Optimization via Reinforcement) and PRM (Probabilistic Reasoning) are competing strategies.
4. **Error Detection**: The "Aha Moment" highlights the importance of reinforcement learning in identifying and correcting mistakes.
---
### Interpretation
The diagram metaphorically represents challenges in AI development:
- **Training → Reasoning**: Initial training enables basic reasoning, but **reasoning boundaries** (Section b) define the limits of model capabilities.
- **Overthinking**: Excessive scaling (Section c) leads to inefficiency, visualized by the collapsed snake.
- **Inference-Time Scaling**: Parallel scaling (Section d) is preferred over sequential for efficiency, though both require careful sampling.
- **ORM vs. PRM**: The selection between these methods (Section e) depends on the problem’s probabilistic vs. optimization requirements.
- **Aha Moment**: The "Aha!" moment (Section f) underscores the role of reinforcement learning in self-correction, critical for refining models.
The diagram emphasizes balancing scalability, avoiding overfitting ("overthinking"), and leveraging error detection to improve AI systems. The snake motif symbolizes adaptability and growth, while the red scarves unify the theme of training across phenomena.