## Chart: Speed and Quality Across Methods
### Overview
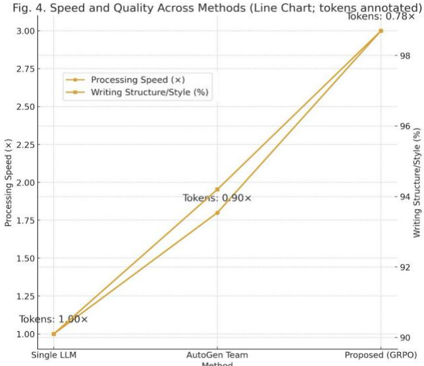
The image is a line chart comparing the processing speed and writing structure/style of three methods: Single LLM, AutoGen Team, and Proposed (GRPO). The chart also annotates the number of tokens for each method.
### Components/Axes
* **Title:** Fig. 4. Speed and Quality Across Methods (Line Chart; tokens annotated)
* **X-axis:** Method (Single LLM, AutoGen Team, Proposed (GRPO))
* **Left Y-axis:** Processing Speed (x), with scale from 1.00 to 3.00 in increments of 0.25.
* **Right Y-axis:** Writing Structure/Style (%), with scale from 90 to 98 in increments of 2.
* **Legend:** Located in the top-left corner.
* Processing Speed (x) - Gold line
* Writing Structure/Style (%) - Gold line
* **Annotations:** "Tokens: [value]x" are placed above each data point.
### Detailed Analysis
* **Processing Speed (x) - Gold Line:**
* **Trend:** The processing speed increases from Single LLM to AutoGen Team to Proposed (GRPO).
* **Data Points:**
* Single LLM: Approximately 1.00x
* AutoGen Team: Approximately 1.85x
* Proposed (GRPO): Approximately 2.95x
* **Writing Structure/Style (%) - Gold Line:**
* **Trend:** The writing structure/style increases from Single LLM to AutoGen Team to Proposed (GRPO).
* **Data Points:**
* Single LLM: Approximately 90.5%
* AutoGen Team: Approximately 94%
* Proposed (GRPO): Approximately 98%
* **Token Annotations:**
* Single LLM: Tokens: 1.00x
* AutoGen Team: Tokens: 0.90x
* Proposed (GRPO): Tokens: 0.78x
### Key Observations
* Both processing speed and writing structure/style improve significantly from Single LLM to Proposed (GRPO).
* The number of tokens decreases from Single LLM to Proposed (GRPO).
* The AutoGen Team method shows a moderate increase in both processing speed and writing structure/style compared to Single LLM.
### Interpretation
The chart suggests that the Proposed (GRPO) method offers a significant improvement in both processing speed and writing structure/style compared to the Single LLM and AutoGen Team methods. This improvement comes at the cost of a reduction in the number of tokens. The data indicates a trade-off between the quantity of tokens and the quality/speed of the output, with the Proposed (GRPO) method prioritizing quality and speed over token count.