\n
## Line Chart: Speed and Quality Across Methods
### Overview
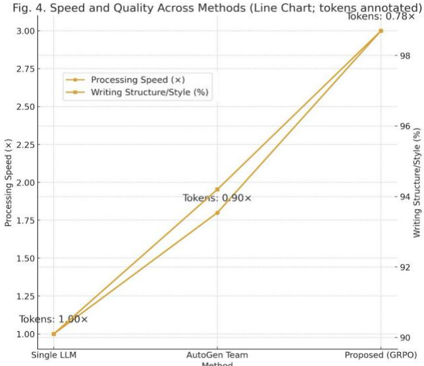
This image presents a line chart comparing the Processing Speed and Writing Structure/Style across three methods: Single LLM, AutoGen Team, and Proposed (GRPO). The chart uses two y-axes to represent these metrics, with the x-axis representing the method. The chart also includes annotations indicating the number of tokens used for each method.
### Components/Axes
* **Title:** "Fig. 4. Speed and Quality Across Methods (Line Chart; tokens annotated)"
* **X-axis:** "Method" with categories: "Single LLM", "AutoGen Team", "Proposed (GRPO)"
* **Left Y-axis:** "Processing Speed (x)" ranging from 1.00 to 3.00, with increments of 0.25.
* **Right Y-axis:** "Writing Structure/Style (%)" ranging from 90 to 98, with increments of 2.
* **Legend:** Located in the top-left corner.
* "Processing Speed (x)" - represented by a solid gold line.
* "Writing Structure/Style (%)" - represented by a dashed gold line.
* **Annotations:**
* "Tokens: 1.00x" positioned near "Single LLM".
* "Tokens: 0.90x" positioned near "AutoGen Team".
* "Tokens: 0.78x" positioned near "Proposed (GRPO)".
### Detailed Analysis
* **Processing Speed (x):**
* The line slopes upward from left to right.
* At "Single LLM", the processing speed is approximately 1.00x.
* At "AutoGen Team", the processing speed is approximately 1.75x.
* At "Proposed (GRPO)", the processing speed is approximately 3.00x.
* **Writing Structure/Style (%):**
* The line also slopes upward from left to right, but with a less steep gradient than the processing speed line.
* At "Single LLM", the writing structure/style is approximately 92%.
* At "AutoGen Team", the writing structure/style is approximately 94%.
* At "Proposed (GRPO)", the writing structure/style is approximately 96%.
### Key Observations
* The "Proposed (GRPO)" method demonstrates the highest processing speed and writing structure/style.
* The "AutoGen Team" method shows a significant improvement in processing speed compared to the "Single LLM" method, with a moderate improvement in writing structure/style.
* The number of tokens used decreases as the method progresses from "Single LLM" to "Proposed (GRPO)".
### Interpretation
The chart suggests that the "Proposed (GRPO)" method offers the best performance in terms of both processing speed and writing quality, while also being the most efficient in terms of token usage. The increasing trend of both metrics indicates a positive correlation between the method and its performance. The decreasing token usage suggests that the "Proposed (GRPO)" method is more optimized for resource utilization. The difference in slope between the two lines indicates that processing speed improves at a faster rate than writing structure/style as the method changes. This could imply that the "Proposed (GRPO)" method prioritizes speed over stylistic refinement, or that the stylistic improvements are less pronounced than the speed gains. The annotations regarding token usage provide additional context, suggesting that the improved performance of the "Proposed (GRPO)" method is achieved with fewer tokens, indicating greater efficiency.