\n
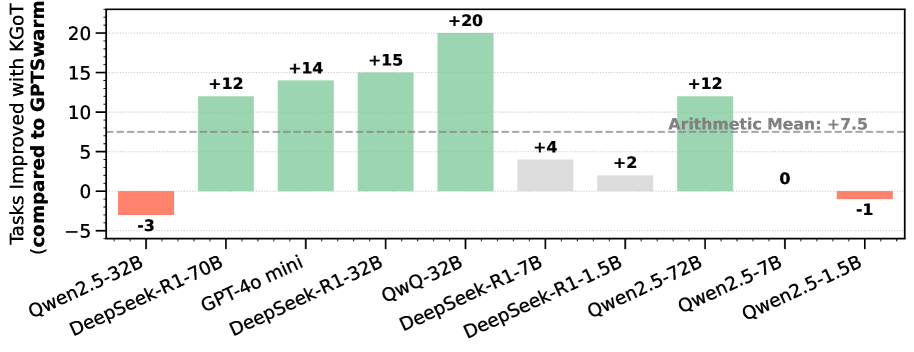
## Bar Chart: Tasks Improved with KGOT (compared to GPT-Swarm)
### Overview
This bar chart visualizes the improvement in the number of tasks completed when using KGOT compared to GPT-Swarm, for various language models. The y-axis represents the number of tasks improved, with positive values indicating improvement and negative values indicating a decrease. The x-axis lists the different language models being compared. A horizontal dashed line indicates the arithmetic mean of the improvements.
### Components/Axes
* **Y-axis Title:** "Tasks Improved with KGOT (compared to GPT-Swarm)" - Scale ranges from approximately -5 to 22.
* **X-axis Labels:** "Qwen2.5-32B", "DeepSeek-R1-70B", "GPT-40 mini", "DeepSeek-R1-32B", "QwQ-32B", "DeepSeek-R1-7B", "DeepSeek-R1-1.5B", "Qwen2.5-72B", "Qwen2.5-7B", "Qwen2.5-1.5B".
* **Horizontal Line:** "Arithmetic Mean: +7.5" - A dashed grey line at approximately y = 7.5.
* **Bar Colors:** Green bars indicate positive improvement, while red bars indicate a decrease in tasks improved.
### Detailed Analysis
The chart displays the following data points:
* **Qwen2.5-32B:** -3 (Red bar)
* **DeepSeek-R1-70B:** +12 (Green bar)
* **GPT-40 mini:** +14 (Green bar)
* **DeepSeek-R1-32B:** +15 (Green bar)
* **QwQ-32B:** +20 (Green bar)
* **DeepSeek-R1-7B:** +4 (Green bar)
* **DeepSeek-R1-1.5B:** +2 (Green bar)
* **Qwen2.5-72B:** +12 (Green bar)
* **Qwen2.5-7B:** 0 (Grey bar)
* **Qwen2.5-1.5B:** -1 (Red bar)
**Trends:**
* The majority of the language models show a positive improvement in tasks completed when using KGOT compared to GPT-Swarm.
* The improvements range from a decrease of 3 tasks (Qwen2.5-32B) to an increase of 20 tasks (QwQ-32B).
* The DeepSeek-R1 models consistently show significant improvements.
* Qwen2.5-7B shows no improvement (0).
* Qwen2.5-32B and Qwen2.5-1.5B show a decrease in tasks improved.
### Key Observations
* QwQ-32B demonstrates the largest improvement (+20 tasks).
* Qwen2.5-32B shows the largest decrease (-3 tasks).
* The arithmetic mean of +7.5 suggests that, on average, KGOT improves task completion across these models.
* The spread of the data points is relatively wide, indicating varying degrees of benefit from KGOT depending on the model.
### Interpretation
The data suggests that KGOT is generally beneficial for improving task completion when compared to GPT-Swarm, as evidenced by the positive arithmetic mean and the prevalence of green bars. However, the effectiveness of KGOT varies significantly across different language models. The substantial improvement observed with QwQ-32B suggests that KGOT may be particularly well-suited for this model's architecture or training data. Conversely, the decrease in performance with Qwen2.5-32B and Qwen2.5-1.5B indicates that KGOT may not be universally applicable and could even be detrimental in certain cases. Further investigation is needed to understand the factors that contribute to these variations and to optimize the use of KGOT for different language models. The fact that the DeepSeek-R1 models consistently perform well with KGOT suggests a potential synergy between the two technologies.