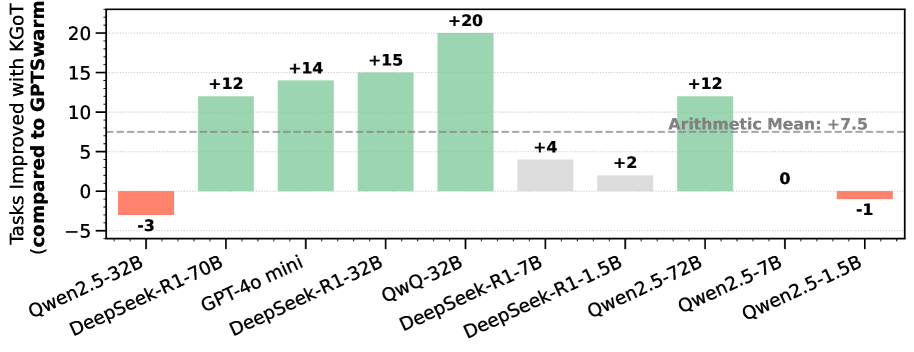
## Bar Chart: Task Performance Comparison Between KGoT and GPTSwarm Models
### Overview
The chart compares task performance improvements (or degradations) when using KGoT versus GPTSwarm across various large language models (LLMs). Bars are color-coded to indicate improvement (+), no change (neutral), or degradation (-). An arithmetic mean line at +7.5 is included for reference.
### Components/Axes
- **X-axis**: LLMs (models) tested:
- Qwen2.5-32B
- DeepSeek-R1-70B
- GPT-4o mini
- DeepSeek-R1-32B
- QwQ-32B
- DeepSeek-R1-7B
- DeepSeek-R1-1.5B
- Qwen2.5-72B
- Qwen2.5-7B
- Qwen2.5-1.5B
- **Y-axis**: "Tasks Improved with KGoT (compared to GPTSwarm)" with values ranging from -5 to +20.
- **Legend** (right side):
- **Green**: "+Improved" (positive task improvement)
- **Gray**: "No change" (neutral performance)
- **Red**: "-Degraded" (task degradation)
- **Arithmetic Mean**: Dashed horizontal line at +7.5.
### Detailed Analysis
1. **Qwen2.5-32B**: Red bar (-3), indicating task degradation.
2. **DeepSeek-R1-70B**: Green bar (+12), significant improvement.
3. **GPT-4o mini**: Green bar (+14), strong improvement.
4. **DeepSeek-R1-32B**: Green bar (+15), highest improvement among smaller models.
5. **QwQ-32B**: Green bar (+20), largest improvement overall.
6. **DeepSeek-R1-7B**: Gray bar (+4), neutral performance.
7. **DeepSeek-R1-1.5B**: Gray bar (+2), minimal improvement.
8. **Qwen2.5-72B**: Green bar (+12), consistent improvement.
9. **Qwen2.5-7B**: Gray bar (0), no change.
10. **Qwen2.5-1.5B**: Red bar (-1), slight degradation.
### Key Observations
- **Positive Trends**: 6/10 models show improvement (green bars), with QwQ-32B (+20) and DeepSeek-R1-32B (+15) leading.
- **Negative Outliers**: Qwen2.5-32B (-3) and Qwen2.5-1.5B (-1) underperform.
- **Neutral Performance**: Three models (DeepSeek-R1-7B, DeepSeek-R1-1.5B, Qwen2.5-7B) show no change or minimal improvement.
- **Mean Context**: The arithmetic mean (+7.5) suggests moderate average improvement, but outliers skew the distribution.
### Interpretation
The data demonstrates that KGoT generally enhances task performance compared to GPTSwarm, particularly for larger models like QwQ-32B and DeepSeek-R1-32B. However, smaller models (e.g., Qwen2.5-32B, Qwen2.5-1.5B) exhibit degradation, suggesting KGoT’s effectiveness may depend on model architecture or scale. The neutral results for mid-sized models (e.g., DeepSeek-R1-7B) highlight variability in KGoT’s impact. The arithmetic mean (+7.5) underscores an overall positive trend but masks significant disparities between models. This analysis implies KGoT could be prioritized for high-performing models while requiring further optimization for smaller architectures.