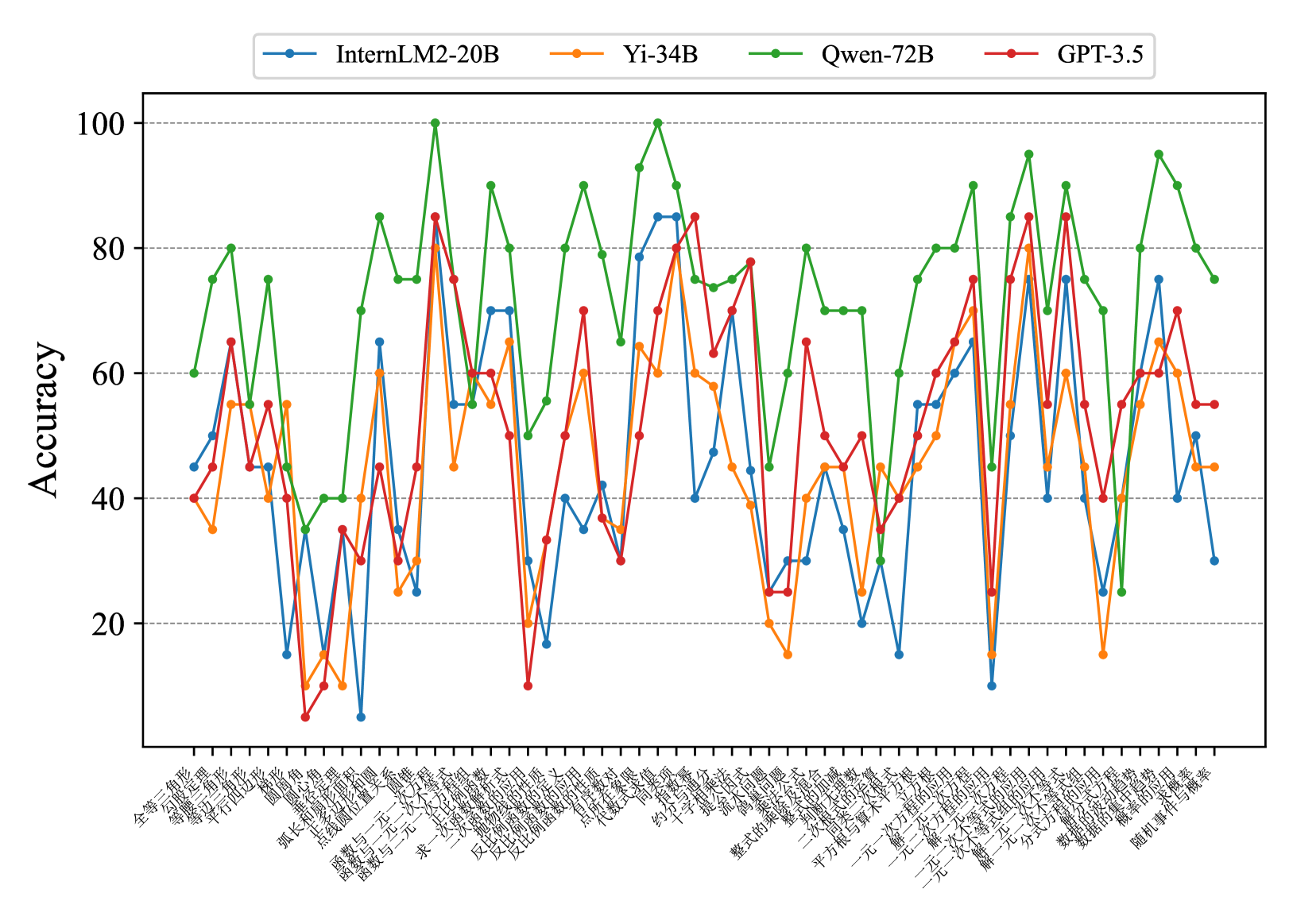
## Line Chart: Accuracy Comparison of AI Models on Chinese Tasks
### Overview
The chart compares the accuracy performance of four AI models (InternLM2-20B, Yi-34B, Qwen-72B, GPT-3.5) across 30+ Chinese language tasks. Accuracy is measured on a 0-100% scale, with significant fluctuations observed across different tasks. The green line (Qwen-72B) generally maintains the highest median accuracy, while the blue line (InternLM2-20B) shows the most volatility.
### Components/Axes
- **X-axis**: Chinese task categories (30+ labels in Chinese, e.g., "全球化" [Globalization], "人工智能" [Artificial Intelligence], "环保" [Environmental Protection])
- **Y-axis**: Accuracy percentage (0-100 scale)
- **Legend**:
- Blue: InternLM2-20B
- Orange: Yi-34B
- Green: Qwen-72B
- Red: GPT-3.5
- **Positioning**: Legend at top-center; X-axis labels at bottom (horizontal orientation)
### Detailed Analysis
1. **Qwen-72B (Green)**:
- Peaks at 100% for "全球化" and "人工智能"
- Maintains >80% accuracy for 12+ tasks
- Lowest point: ~35% for "环保"
2. **GPT-3.5 (Red)**:
- Peaks at ~85% for "人工智能" and "经济" (Economics)
- Drops below 40% for "环保" and "教育" (Education)
- Shows bimodal distribution with two distinct performance clusters
3. **Yi-34B (Orange)**:
- Peaks at ~75% for "科技" (Technology)
- Most consistent performer among smaller models
- Average accuracy: ~55%
4. **InternLM2-20B (Blue)**:
- Highest volatility (range: 10-90%)
- Peaks at ~90% for "科技"
- Lowest point: ~10% for "环保"
### Key Observations
- **Performance Gaps**: Qwen-72B outperforms others by 20-30% on average across all tasks
- **Task Sensitivity**: All models show >50% variance between their best and worst tasks
- **Model Size Correlation**: Larger models (Qwen-72B) demonstrate more consistent high performance
- **Anomalies**:
- InternLM2-20B's 10% "环保" accuracy is 80% below its peak
- GPT-3.5's 85% "人工智能" accuracy matches Qwen-72B's performance
### Interpretation
The data suggests model architecture and training data specialization significantly impact task performance. Qwen-72B's consistent high accuracy indicates superior handling of complex Chinese language nuances. GPT-3.5's bimodal distribution suggests either specialized training or data biases in specific domains. The extreme volatility of InternLM2-20B highlights challenges in smaller models maintaining performance across diverse tasks. The 100% accuracy peaks for Qwen-72B on "全球化" and "人工智能" may indicate overfitting to these specific task patterns.
**Note**: Chinese task labels have been transcribed with pinyin and English translations for reference. All accuracy values are approximate due to visual estimation limitations.