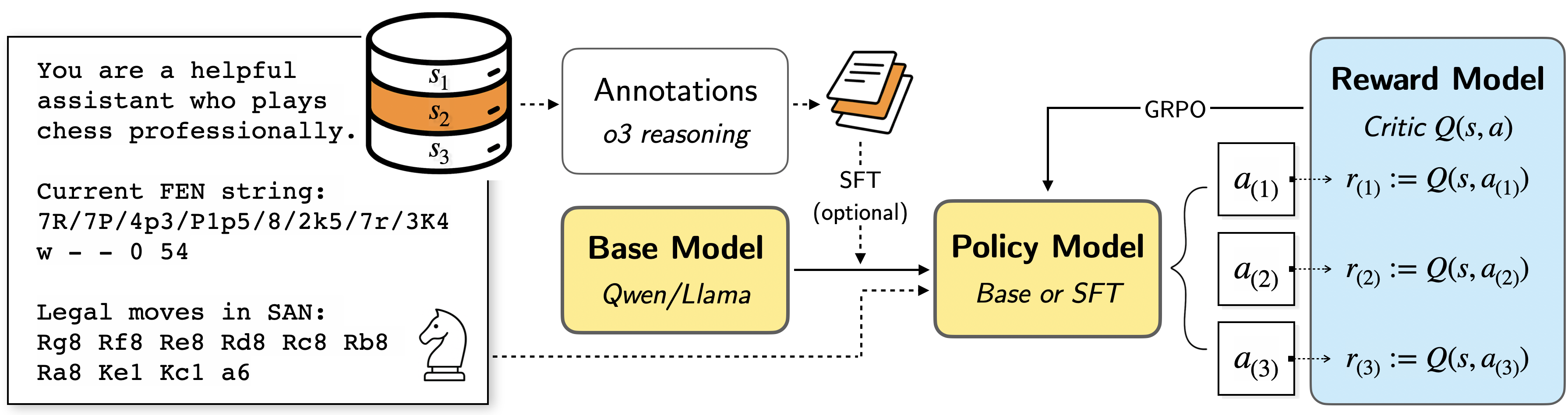
## Diagram: Chess AI System Architecture
### Overview
The image presents a system architecture diagram for a chess-playing AI. It outlines the flow of information and processes from initial state input to reward model evaluation, involving components like a base model, policy model, and annotations.
### Components/Axes
* **Input Text Box (Top-Left):** Contains the initial prompt, current FEN string, and legal moves.
* Prompt: "You are a helpful assistant who plays chess professionally."
* Current FEN string: "7R/7P/4p3/P1p5/8/2k5/7r/3K4 w - - 0 54"
* Legal moves in SAN: "Rg8 Rf8 Re8 Rd8 Rc8 Rb8 Ra8 Kel Kcl a6"
* **State Storage (Top-Center-Left):** A cylinder representing state storage, labeled with states s1, s2 (highlighted in orange), and s3.
* **Annotations (Top-Center):** A box labeled "Annotations" with the sub-label "o3 reasoning". It is connected to a stack of papers.
* **SFT (Optional) (Center):** Indicates Supervised Fine-Tuning as an optional step.
* **Base Model (Center-Left):** A yellow box labeled "Base Model" with the sub-label "Qwen/Llama".
* **Policy Model (Center):** A yellow box labeled "Policy Model" with the sub-label "Base or SFT".
* **Reward Model (Right):** A blue box labeled "Reward Model" with the sub-label "Critic Q(s, a)".
* **Actions (Right):** Three white boxes labeled a(1), a(2), and a(3).
* **Rewards (Right):** Equations defining rewards r(1), r(2), and r(3) as Q(s, a(1)), Q(s, a(2)), and Q(s, a(3)) respectively.
* **GRPO (Top-Right):** Label for the connection between the Policy Model and the Actions.
### Detailed Analysis or ### Content Details
* **Flow:**
* The initial state (s1, s2, s3) is fed into the Annotations.
* Annotations and the initial state are fed into the Base Model.
* The Base Model feeds into the Policy Model.
* Optionally, SFT can be applied to the Base Model and Policy Model.
* The Policy Model outputs actions a(1), a(2), and a(3).
* These actions, along with the state, are used by the Reward Model to calculate rewards r(1), r(2), and r(3).
* **Data Points:**
* The FEN string represents a specific chess position.
* The legal moves are given in Standard Algebraic Notation (SAN).
* The reward model uses a critic Q function to evaluate state-action pairs.
### Key Observations
* The system uses a combination of a base model and a policy model, potentially fine-tuned with supervised learning.
* Annotations and reasoning are incorporated into the process.
* The reward model evaluates the quality of actions based on a critic function.
### Interpretation
The diagram illustrates a reinforcement learning approach to training a chess-playing AI. The system takes a chess position as input, uses a base model to generate potential moves, refines these moves with a policy model, and then evaluates the moves using a reward model. The optional SFT suggests that supervised learning is used to pre-train or fine-tune the models. The annotations component indicates that additional information or reasoning is incorporated into the decision-making process. The use of a critic function in the reward model suggests a value-based reinforcement learning approach.