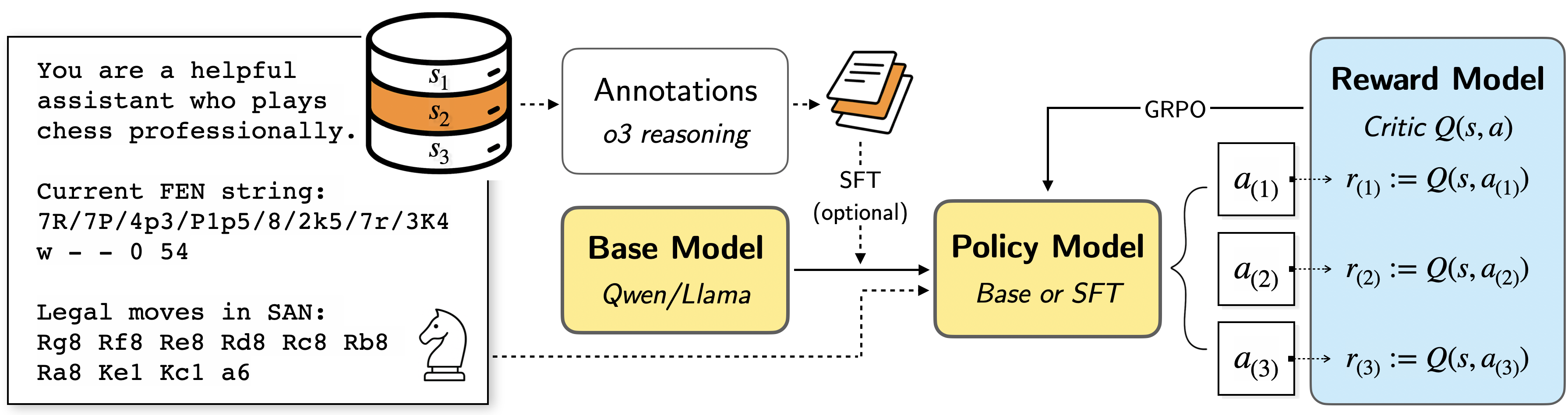
## Diagram: Chess AI System Architecture
### Overview
The diagram illustrates a chess-playing AI system architecture with multiple interconnected components. It shows the flow from chess position analysis through model processing to action selection and reward evaluation. The system uses chess-specific notation (FEN/SAN) and incorporates reinforcement learning concepts.
### Components/Axes
1. **Left Panel (Textual Context)**
- Role description: "helpful assistant who plays chess professionally"
- Chess position: FEN string "7R/7P/4p3/P1p5/8/2k5/7r/3K4 w - - 0 54"
- Legal moves in SAN:
- Rg8 Rf8 Re8 Rd8 Rc8 Rb8
- Ra8 Ke1 Kc1 a6
- Chess piece icon (knight)
2. **Central Processing Flow**
- Cylindrical diagram with stages S1 (white), S2 (orange), S3 (white)
- Annotation stack with "Annotations o3 reasoning" and SFT (optional)
- Base Model (Qwen/Llama) connected to Policy Model (Base or SFT)
- Policy Model outputs actions a1, a2, a3
3. **Right Panel (Reward System)**
- Reward Model (blue box) with Critic Q(s,a) function
- GRPO (Gradient-based Reinforcement Optimization) connection
- Reward calculations:
- r₁ := Q(s, a₁)
- r₂ := Q(s, a₂)
- r₃ := Q(s, a₃)
### Detailed Analysis
- **Chess Position**: The FEN string describes a specific board state with white pieces on ranks 1-2 and black pieces on ranks 7-8, with a white king on e1 and black king on c1.
- **Model Architecture**:
- Base Model (Qwen/Llama) processes chess positions
- Policy Model selects actions (a1-a3) using either Base Model or SFT
- Reward Model evaluates actions using Q(s,a) critic function
- **Reinforcement Learning**: GRPO optimization connects Policy Model to Reward Model
- **Notation Systems**: Uses both FEN (position encoding) and SAN (move notation)
### Key Observations
1. The orange-highlighted S2 stage suggests special processing or emphasis
2. SFT (Supervised Fine-Tuning) is marked as optional in the annotation flow
3. Multiple reward calculations (r₁-r₃) indicate parallel action evaluation
4. Chess-specific terminology dominates the textual components
5. The knight icon visually reinforces the chess context
### Interpretation
This architecture demonstrates a hybrid approach combining:
1. **Chess Domain Knowledge**: Explicit FEN/SAN notation handling
2. **AI Models**: Base/Llama models for position analysis
3. **Reinforcement Learning**: GRPO optimization for policy improvement
4. **Human-like Expertise**: The "professional chess player" role description suggests human-AI collaboration
The system appears designed to:
1. Analyze complex chess positions (FEN string)
2. Generate legal moves (SAN notation)
3. Evaluate actions through multiple reward calculations
4. Optimize policy using gradient-based methods
The orange-highlighted S2 stage might represent a critical decision point in the processing pipeline, possibly where the most computationally intensive analysis occurs. The optional SFT component suggests flexibility in model training approaches.