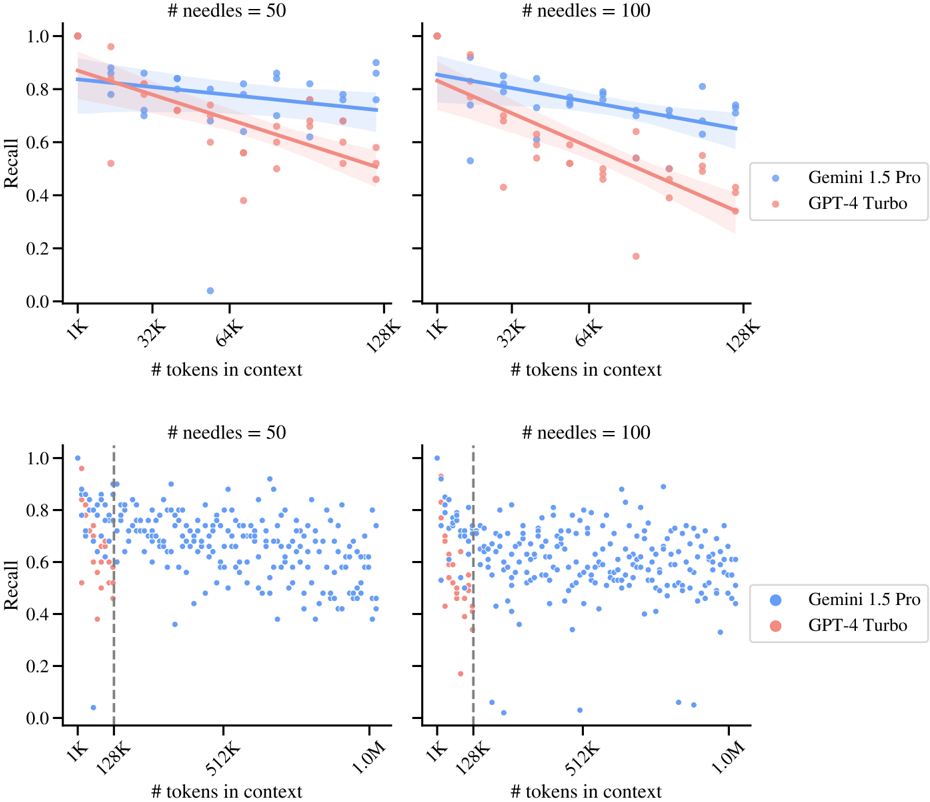
## Scatter Plot: Recall vs. Context Length for Language Models
### Overview
The image presents four scatter plots comparing the recall performance of two language models, Gemini 1.5 Pro (blue) and GPT-4 Turbo (red), across varying context lengths and two different settings of '# needles' (50 and 100). The top two plots show the trend lines with shaded confidence intervals, while the bottom two plots show the raw data points. The x-axis represents the number of tokens in context, and the y-axis represents the recall score.
### Components/Axes
* **Title (Top-Left & Top-Right)**: "# needles = 50" and "# needles = 100" respectively. This indicates the number of needles used in the evaluation.
* **Title (Bottom-Left & Bottom-Right)**: "# needles = 50" and "# needles = 100" respectively. This indicates the number of needles used in the evaluation.
* **Y-axis Label**: "Recall" (ranges from 0.0 to 1.0 in increments of 0.2).
* **X-axis Label**: "# tokens in context".
* Top plots: X-axis ranges from 1K to 128K. Axis markers are present at 1K, 32K, 64K, and 128K.
* Bottom plots: X-axis ranges from 1K to 1.0M. Axis markers are present at 1K, 128K, 512K, and 1.0M.
* **Legend (Right)**:
* Blue: "Gemini 1.5 Pro"
* Red: "GPT-4 Turbo"
* **Vertical Dashed Line (Bottom Plots)**: Located at 128K on the x-axis.
### Detailed Analysis
**Top Plots (Trend Lines)**
* **# needles = 50 (Top-Left)**:
* **Gemini 1.5 Pro (Blue)**: The trend line starts at approximately 0.85 recall at 1K tokens and decreases slightly to approximately 0.75 recall at 128K tokens.
* **GPT-4 Turbo (Red)**: The trend line starts at approximately 0.80 recall at 1K tokens and decreases to approximately 0.55 recall at 128K tokens.
* **# needles = 100 (Top-Right)**:
* **Gemini 1.5 Pro (Blue)**: The trend line starts at approximately 0.85 recall at 1K tokens and decreases to approximately 0.70 recall at 128K tokens.
* **GPT-4 Turbo (Red)**: The trend line starts at approximately 0.85 recall at 1K tokens and decreases to approximately 0.50 recall at 128K tokens.
**Bottom Plots (Scatter Plots)**
* **# needles = 50 (Bottom-Left)**:
* **Gemini 1.5 Pro (Blue)**: Data points are scattered between approximately 0.4 and 1.0 recall across the entire context length range (1K to 1.0M). The density of points appears relatively consistent after 128K.
* **GPT-4 Turbo (Red)**: Data points are scattered between approximately 0.4 and 1.0 recall up to 128K tokens. After 128K, there are very few data points.
* **# needles = 100 (Bottom-Right)**:
* **Gemini 1.5 Pro (Blue)**: Data points are scattered between approximately 0.4 and 1.0 recall across the entire context length range (1K to 1.0M). The density of points appears relatively consistent after 128K.
* **GPT-4 Turbo (Red)**: Data points are scattered between approximately 0.4 and 1.0 recall up to 128K tokens. After 128K, there are very few data points.
### Key Observations
* In the top plots, for both #needles values, Gemini 1.5 Pro consistently outperforms GPT-4 Turbo in terms of recall across the context length range.
* The recall for both models tends to decrease as the context length increases, as shown by the downward sloping trend lines in the top plots.
* The bottom plots show that the recall values are more scattered, especially for Gemini 1.5 Pro, indicating variability in performance.
* GPT-4 Turbo has very few data points beyond 128K tokens in the bottom plots, suggesting that the model's performance was not evaluated or is not reliable beyond this context length.
* The vertical dashed line at 128K in the bottom plots may indicate a significant threshold or change in evaluation methodology.
### Interpretation
The data suggests that Gemini 1.5 Pro generally maintains a higher recall performance compared to GPT-4 Turbo, especially as the context length increases. The decreasing trend in recall for both models with increasing context length could indicate challenges in maintaining information retrieval accuracy within longer contexts. The limited data for GPT-4 Turbo beyond 128K tokens raises questions about its performance and evaluation in extended context scenarios. The number of needles does not appear to drastically change the overall trends, but a higher number of needles (=100) seems to slightly exacerbate the performance gap between the two models. The scatter plots highlight the variability in recall performance, suggesting that individual instances can deviate significantly from the average trend.