\n
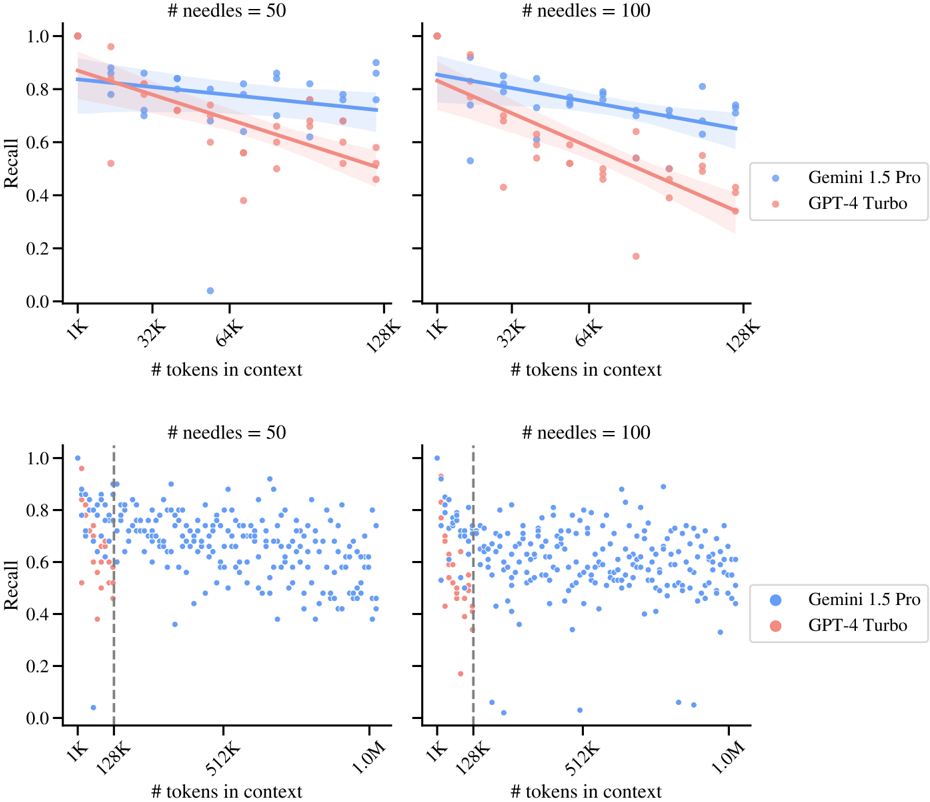
## Scatter Plot: Recall vs. Tokens in Context for LLMs
### Overview
The image presents four scatter plots arranged in a 2x2 grid, comparing the performance of two Large Language Models (LLMs), Gemini 1.5 Pro and GPT-4 Turbo, based on their 'Recall' score as a function of '# tokens in context'. Each plot represents a different number of 'needles' (50 or 100). Each plot also includes a regression line with a shaded confidence interval for each model.
### Components/Axes
* **X-axis:** '# tokens in context'. Scales vary per plot:
* Top Left & Right: 1K, 32K, 64K, 128K
* Bottom Left & Right: 1K, 128K, 512K, 1.0M
* **Y-axis:** 'Recall'. Scale: 0.0 to 1.0
* **Legend:** Located in the bottom-right corner of the combined plots.
* Gemini 1.5 Pro (Blue)
* GPT-4 Turbo (Orange/Red)
* **Title:** Each plot is labeled with '# needles = [50 or 100]' at the top.
### Detailed Analysis or Content Details
**Top Left Plot (# needles = 50, X-axis: 1K - 128K)**
* **Gemini 1.5 Pro (Blue):** The data points are scattered, but generally cluster between 0.6 and 0.9. The regression line slopes downward, indicating a negative correlation between tokens in context and recall.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.85
* 32K tokens: Recall ~ 0.75
* 64K tokens: Recall ~ 0.70
* 128K tokens: Recall ~ 0.65
* **GPT-4 Turbo (Orange):** The data points are more spread out, with a wider range of recall values (0.2 to 1.0). The regression line also slopes downward, but is steeper than Gemini 1.5 Pro's.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.90
* 32K tokens: Recall ~ 0.60
* 64K tokens: Recall ~ 0.45
* 128K tokens: Recall ~ 0.30
**Top Right Plot (# needles = 100, X-axis: 1K - 128K)**
* **Gemini 1.5 Pro (Blue):** Similar to the top-left plot, the data points cluster between 0.6 and 0.9, with a downward sloping regression line.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.80
* 32K tokens: Recall ~ 0.70
* 64K tokens: Recall ~ 0.65
* 128K tokens: Recall ~ 0.60
* **GPT-4 Turbo (Orange):** Again, more spread out than Gemini 1.5 Pro, with a steeper downward sloping regression line.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.85
* 32K tokens: Recall ~ 0.55
* 64K tokens: Recall ~ 0.40
* 128K tokens: Recall ~ 0.25
**Bottom Left Plot (# needles = 50, X-axis: 1K - 1.0M)**
* **Gemini 1.5 Pro (Blue):** Data points are densely scattered, mostly between 0.6 and 0.9. The regression line is relatively flat.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.85
* 128K tokens: Recall ~ 0.70
* 512K tokens: Recall ~ 0.65
* 1.0M tokens: Recall ~ 0.60
* **GPT-4 Turbo (Orange):** Data points are more dispersed, with a slight downward trend.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.90
* 128K tokens: Recall ~ 0.50
* 512K tokens: Recall ~ 0.35
* 1.0M tokens: Recall ~ 0.30
**Bottom Right Plot (# needles = 100, X-axis: 1K - 1.0M)**
* **Gemini 1.5 Pro (Blue):** Similar to the bottom-left plot, data points are densely scattered, mostly between 0.6 and 0.9. The regression line is relatively flat.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.80
* 128K tokens: Recall ~ 0.65
* 512K tokens: Recall ~ 0.60
* 1.0M tokens: Recall ~ 0.55
* **GPT-4 Turbo (Orange):** Data points are more dispersed, with a slight downward trend.
* Approximate data points (visually estimated):
* 1K tokens: Recall ~ 0.85
* 128K tokens: Recall ~ 0.50
* 512K tokens: Recall ~ 0.35
* 1.0M tokens: Recall ~ 0.30
### Key Observations
* Both models exhibit a general trend of decreasing recall as the number of tokens in context increases, particularly at lower needle counts (50).
* GPT-4 Turbo generally has higher recall at 1K tokens but declines more rapidly with increasing tokens in context compared to Gemini 1.5 Pro.
* Gemini 1.5 Pro demonstrates more stable recall performance across a wider range of tokens in context, especially at higher token counts (512K and 1.0M).
* Increasing the number of 'needles' from 50 to 100 appears to slightly decrease the overall recall for both models.
### Interpretation
The data suggests that Gemini 1.5 Pro is more robust to increases in context length than GPT-4 Turbo, maintaining a relatively stable recall score even with a large number of tokens in context. GPT-4 Turbo, while performing well with limited context, suffers a more significant drop in recall as the context window expands. The 'needles' parameter likely represents the complexity or number of relevant pieces of information the model needs to retrieve. The decrease in recall with increasing needles suggests that both models struggle to maintain accuracy when faced with more complex retrieval tasks. The relatively flat regression lines for Gemini 1.5 Pro at higher token counts indicate that it can effectively leverage larger context windows without significant performance degradation. This could be due to architectural differences or training methodologies. The data highlights the trade-off between context length and recall, and the importance of choosing a model that is well-suited to the specific task and context requirements.