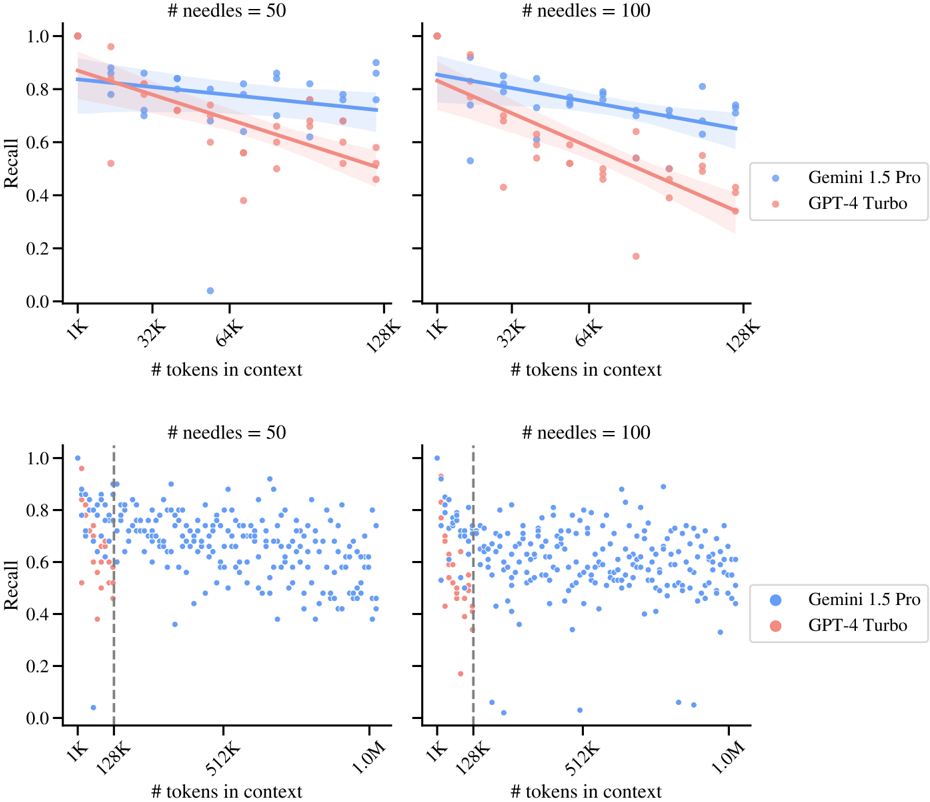
## Scatter Plots: Recall vs. Tokens in Context for Gemini 1.5 Pro and GPT-4 Turbo
### Overview
The image contains four scatter plots comparing the recall performance of two language models (Gemini 1.5 Pro and GPT-4 Turbo) across varying context lengths (tokens in context) and needle counts (50 or 100). Each plot includes a trendline with confidence intervals and raw data points.
### Components/Axes
- **X-axis**: "# tokens in context" (ranges: 1K–128K for top plots; 1K–1M for bottom plots)
- **Y-axis**: "Recall" (0.0–1.0 scale)
- **Legends**:
- Blue dots: Gemini 1.5 Pro
- Red dots: GPT-4 Turbo
- **Additional elements**:
- Shaded regions: 95% confidence intervals for trendlines
- Vertical dashed line at 128K tokens (bottom plots only)
### Detailed Analysis
#### Top-Left Plot (# needles = 50, x-axis: 1K–128K)
- **Trend**: Both models show a slight downward slope in recall as tokens increase.
- **Gemini 1.5 Pro**:
- Recall starts near 0.85 at 1K tokens, declines to ~0.75 at 128K.
- Confidence interval narrows slightly with more tokens.
- **GPT-4 Turbo**:
- Recall starts near 0.75 at 1K tokens, declines to ~0.55 at 128K.
- Confidence interval widens more noticeably.
#### Top-Right Plot (# needles = 100, x-axis: 1K–128K)
- **Trend**: Similar downward slope, but Gemini maintains a steeper advantage.
- **Gemini 1.5 Pro**:
- Recall starts near 0.85 at 1K tokens, declines to ~0.78 at 128K.
- **GPT-4 Turbo**:
- Recall starts near 0.70 at 1K tokens, declines to ~0.50 at 128K.
#### Bottom-Left Plot (# needles = 50, x-axis: 1K–1M)
- **Trend**: Recall drops sharply for both models beyond 128K tokens.
- **Gemini 1.5 Pro**:
- Recall stabilizes around 0.70–0.75 between 128K and 1M tokens.
- **GPT-4 Turbo**:
- Recall drops to ~0.40 at 1M tokens.
- **Vertical line at 128K**: Highlights a performance threshold.
#### Bottom-Right Plot (# needles = 100, x-axis: 1K–1M)
- **Trend**: Similar stabilization for Gemini, but GPT-4 Turbo declines further.
- **Gemini 1.5 Pro**:
- Recall remains ~0.70–0.75 across all tokens.
- **GPT-4 Turbo**:
- Recall drops to ~0.35 at 1M tokens.
### Key Observations
1. **Gemini 1.5 Pro consistently outperforms GPT-4 Turbo** across all context lengths and needle counts.
2. **Recall declines with longer context** for both models, but Gemini’s decline is less steep.
3. **Needle count impacts performance**: Higher needle counts (100) reduce recall more significantly for GPT-4 Turbo.
4. **Confidence intervals widen** for GPT-4 Turbo, indicating greater variability in performance.
### Interpretation
The data suggests Gemini 1.5 Pro maintains higher recall efficiency in long-context tasks, even with increased complexity (more needles). GPT-4 Turbo’s performance degrades more sharply as context length grows, particularly beyond 128K tokens. The vertical threshold at 128K in the bottom plots may indicate a practical limit for GPT-4 Turbo’s effectiveness in long-context retrieval. These trends highlight Gemini’s potential advantage in applications requiring large-scale context processing, such as document analysis or multi-document QA systems.