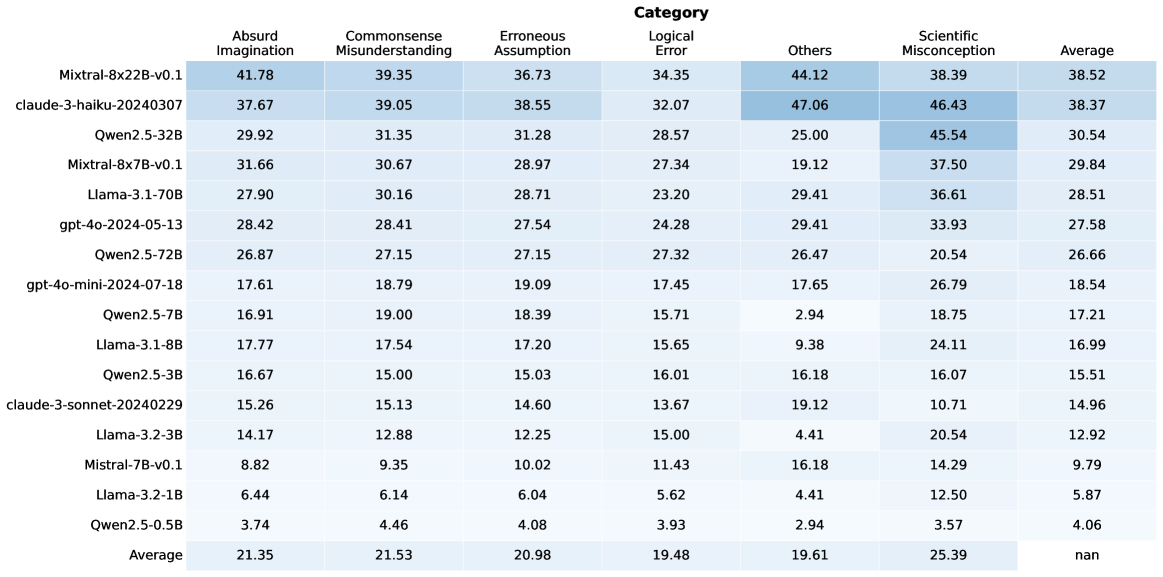
## Table: Model Performance Across Cognitive Error Categories
### Overview
The table presents a comparative analysis of 16 AI models across seven cognitive error categories: Absurd Imagination, Commonsense Misunderstanding, Erroneous Assumption, Logical Error, Others, Scientific Misconception, and Average. Each row represents a specific model/system, with numerical values indicating performance metrics (likely error rates or confidence scores). The final row shows category averages across all models.
### Components/Axes
- **Rows**: 16 models/systems (e.g., Mixtral-8x22B-v0.1, claud 3-haiku-20240307, Qwen2.5-32B)
- **Columns**:
1. Absurd Imagination
2. Commonsense Misunderstanding
3. Erroneous Assumption
4. Logical Error
5. Others
6. Scientific Misconception
7. Average
- **Values**: Numerical scores (e.g., 41.78, 39.35) with decimal precision to two places.
### Detailed Analysis
#### Model Performance Breakdown
1. **Mixtral-8x22B-v0.1**
- Highest in Absurd Imagination (41.78) and Others (44.12)
- Scientific Misconception: 38.39
- Average: 38.52
2. **claud 3-haiku-20240307**
- Highest in Others (47.06) and Scientific Misconception (46.43)
- Average: 38.37
3. **Qwen2.5-32B**
- Highest Scientific Misconception (45.54)
- Average: 30.54
4. **Llama-3-1-70B**
- Balanced performance: 27.90 (Absurd), 30.16 (Commonsense), 36.61 (Scientific)
- Average: 28.51
5. **gpt-4o-2024-05-13**
- Moderate scores across categories (28.42–33.93)
- Average: 27.58
6. **Qwen2.5-72B**
- Lower in Absurd (26.87) but high in Others (26.47)
- Average: 26.66
7. **gpt-4o-mini-2024-07-18**
- Lowest in Absurd (17.61) and Commonsense (18.79)
- Average: 18.54
8. **Llama-3-1-8B**
- Lowest in Absurd (17.77) and Commonsense (17.54)
- Average: 16.99
9. **Qwen2.5-5B**
- Lowest in Absurd (3.74) and Commonsense (4.46)
- Average: 4.06
#### Category Averages
- **Absurd Imagination**: 21.35
- **Commonsense Misunderstanding**: 21.53
- **Erroneous Assumption**: 20.98
- **Logical Error**: 19.48
- **Others**: 19.61
- **Scientific Misconception**: 25.39
### Key Observations
1. **Outliers**:
- `claud 3-haiku-20240307` dominates in "Others" (47.06) and "Scientific Misconception" (46.43).
- `Qwen2.5-5B` has the lowest scores in Absurd (3.74) and Commonsense (4.46).
2. **Trends**:
- "Others" and "Scientific Misconception" categories show higher variability and averages compared to other categories.
- Larger models (e.g., Mixtral-8x22B, Qwen2.5-32B) generally perform better in complex categories like Scientific Misconception.
3. **Averages**:
- The "Average" column suggests most models struggle most with Scientific Misconception (25.39) and Others (19.61).
### Interpretation
The data highlights significant disparities in model performance across cognitive error types. Larger models (e.g., Mixtral-8x22B, Qwen2.5-32B) excel in handling complex errors like Scientific Misconception, while smaller models (e.g., Qwen2.5-5B) underperform in foundational categories like Absurd Imagination. The "Others" category, which aggregates unspecified errors, shows the highest average variability, suggesting it may encompass diverse failure modes. The stark contrast between high-performing models (e.g., claud 3-haiku) and low-performing ones (e.g., Qwen2.5-5B) underscores the need for targeted improvements in specific error categories.