\n
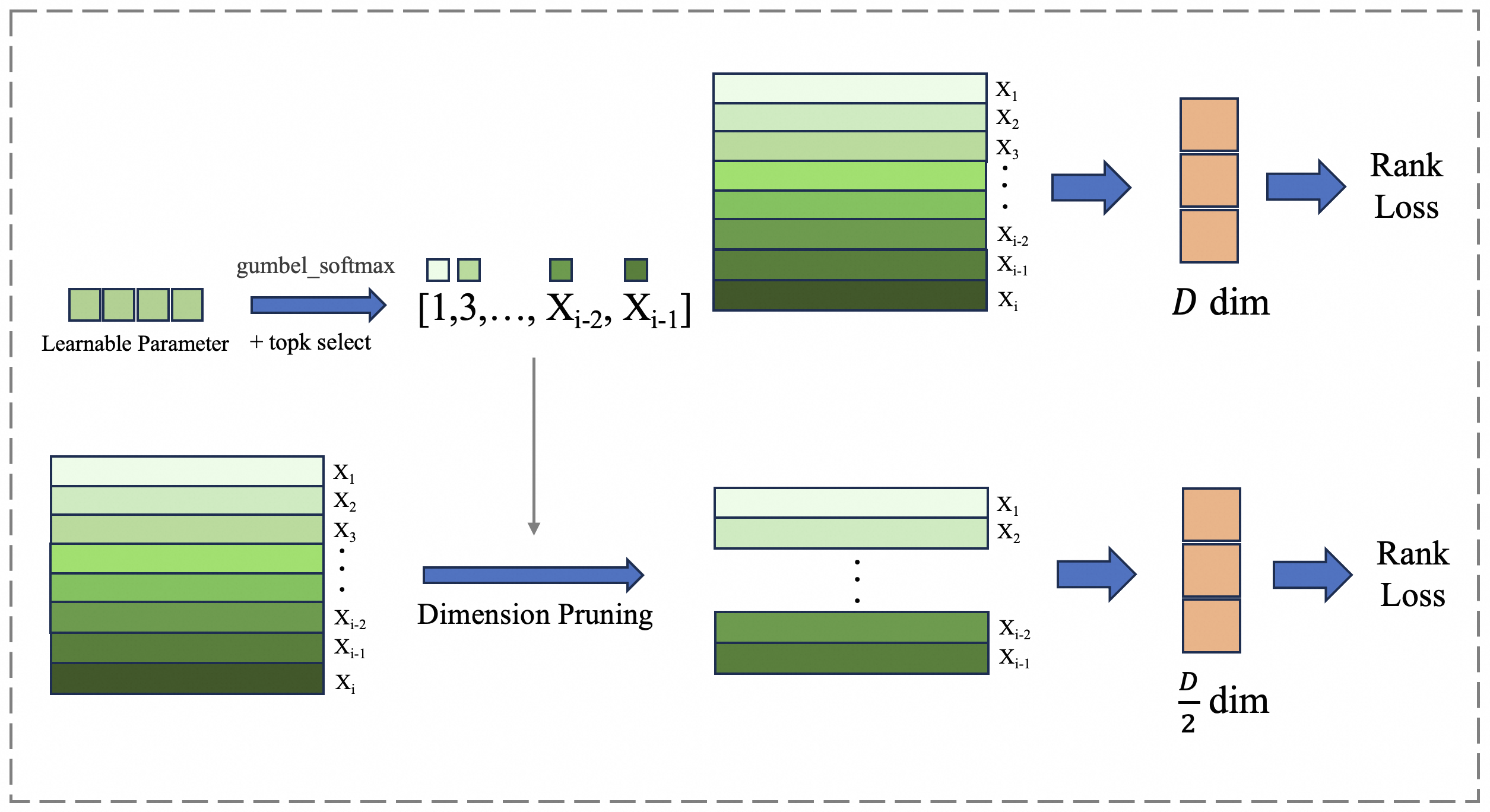
## Diagram: Dimension Pruning with Gumbel-Softmax
### Overview
This diagram illustrates a process of dimension pruning using a Gumbel-Softmax layer, followed by a Rank Loss calculation. The diagram shows two parallel processing paths: one with the full dimension (D dim) and another with a reduced dimension (D/2 dim) after pruning. The process involves a learnable parameter and top-k selection via Gumbel-Softmax, leading to dimension pruning and subsequent Rank Loss computation.
### Components/Axes
The diagram consists of the following components:
* **Learnable Parameter + topk select:** Represented by a purple rectangle.
* **Gumbel Softmax:** Indicated by a light blue arrow.
* **Dimension Pruning:** Represented by a large grey arrow.
* **Input Feature Matrix:** Represented by a green rectangle with labeled rows (X1 to Xi).
* **Rank Loss:** Represented by an orange rectangle.
* **Dimension Labels:** D dim and D/2 dim, indicating the dimensionality of the feature vectors.
* **Index Selection:** [1,3,…,Xi-2, Xi-1]
### Detailed Analysis
The diagram shows two parallel paths.
**Top Path (Full Dimension):**
1. A "Learnable Parameter + topk select" (purple rectangle) feeds into a "Gumbel Softmax" layer (light blue arrow).
2. The output of the Gumbel Softmax is applied to an input feature matrix (green rectangle) with 'i' rows labeled X1 to Xi.
3. The feature matrix is then passed to a Rank Loss calculation (orange rectangle).
4. The output dimension is labeled as "D dim".
**Bottom Path (Pruned Dimension):**
1. The "Learnable Parameter + topk select" (purple rectangle) also feeds into a "Gumbel Softmax" layer (light blue arrow).
2. The output of the Gumbel Softmax is used for "Dimension Pruning" (grey arrow), reducing the input feature matrix.
3. The pruned feature matrix (green rectangle) with 'i-1' rows labeled X1 to Xi-1 is then passed to a Rank Loss calculation (orange rectangle).
4. The output dimension is labeled as "D/2 dim".
The index selection [1,3,…,Xi-2, Xi-1] indicates that the pruning process selects specific dimensions (odd-numbered in this case) from the original feature matrix.
### Key Observations
* The diagram illustrates a method for reducing the dimensionality of feature vectors.
* The Gumbel-Softmax layer appears to be used for differentiable selection of dimensions.
* The Rank Loss is calculated on both the full-dimensional and pruned feature vectors.
* The pruning process appears to select a subset of the original dimensions, resulting in a reduced dimensionality.
### Interpretation
The diagram depicts a technique for learning which dimensions of a feature vector are most important. The Gumbel-Softmax layer provides a differentiable way to select a subset of dimensions, and the Rank Loss function encourages the model to learn a representation where the selected dimensions are more informative. The two parallel paths allow for comparison between the full-dimensional and pruned representations, potentially improving the efficiency and performance of the model. The selection of odd-numbered dimensions [1,3,…,Xi-2, Xi-1] suggests a specific pruning strategy, but the diagram doesn't provide information on why this strategy is chosen. The use of Rank Loss implies that the goal is to learn a ranking of the dimensions based on their importance. This could be useful for feature selection, dimensionality reduction, or model compression.