## Diagram: Parameter Optimization and Dimension Pruning Process
### Overview
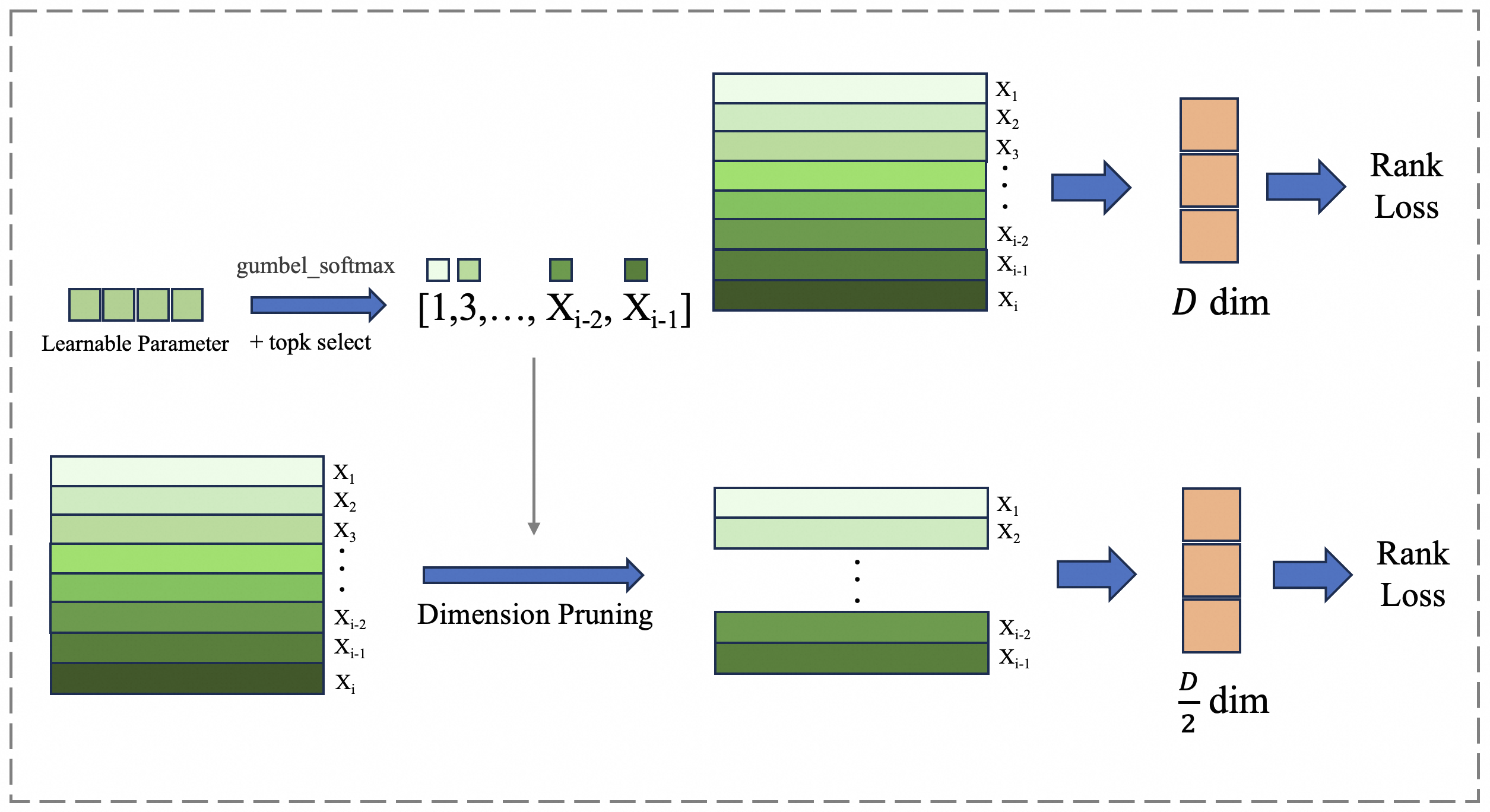
The diagram illustrates a two-stage process for optimizing learnable parameters in a neural network, involving stochastic sampling and dimensionality reduction. It shows how parameters are selected, pruned, and evaluated through rank loss metrics.
### Components/Axes
1. **Left Section (Learnable Parameter + topk select)**:
- **Input**: "Learnable Parameter" block with four green rectangles
- **Process**:
- "gumbel_softmax" operation (blue arrow)
- "topk select" operation (blue arrow)
- **Output**: Sequence of layers labeled [1,3,...,X_{i-2}, X_{i-1}]
- **Layer Stack**:
- X1 (lightest green)
- X2 (medium green)
- X3 (darker green)
- ...
- X_{i-2} (darkest green)
- X_{i-1} (darkest green)
- X_i (darkest green)
2. **Right Section (Dimension Pruning)**:
- **Input**: Full layer stack (X1 to X_i)
- **Process**: "Dimension Pruning" (blue arrow)
- **Output**: Pruned layer stack (X1, X2, ..., X_{i-2}, X_{i-1})
- **Dimensionality**: Reduced to D/2 dimensions
3. **Final Output**:
- "Rank Loss" metric (red block)
- Connection to both processing paths via blue arrows
### Detailed Analysis
- **Color Coding**:
- Green gradient represents parameter importance (light = less important, dark = more important)
- Red block for rank loss (critical evaluation metric)
- **Key Elements**:
- Gumbel-softmax: Stochastic sampling method for differentiable top-k selection
- Top-k selection: Identifies most important parameters
- Dimension pruning: Reduces computational complexity by half
- Rank loss: Measures performance degradation after pruning
### Key Observations
1. The process maintains critical parameters (darkest green layers) while pruning less important ones
2. Dimensionality reduction occurs after parameter selection, not before
3. Both processing paths converge on the same rank loss metric
4. The pruned version maintains the same evaluation standard as the full model
### Interpretation
This diagram demonstrates a parameter optimization strategy that:
1. Uses stochastic sampling (gumbel-softmax) to identify important parameters
2. Applies top-k selection to retain only the most critical parameters
3. Reduces dimensionality by half while preserving performance (as measured by rank loss)
4. Maintains evaluation consistency between full and pruned models
The process suggests a balance between computational efficiency (through pruning) and model performance (through careful parameter selection). The use of rank loss as the final metric indicates that the optimization aims to preserve the relative ordering/importance of parameters rather than absolute values.